朱雀大模型检测对话式隐身术:2025 最新防检测技巧解析
5.3k 阅读
19 评论
🔍 朱雀大模型检测对话式隐身术:2025 最新防检测技巧解析
🔎 朱雀大模型检测机制深度解析
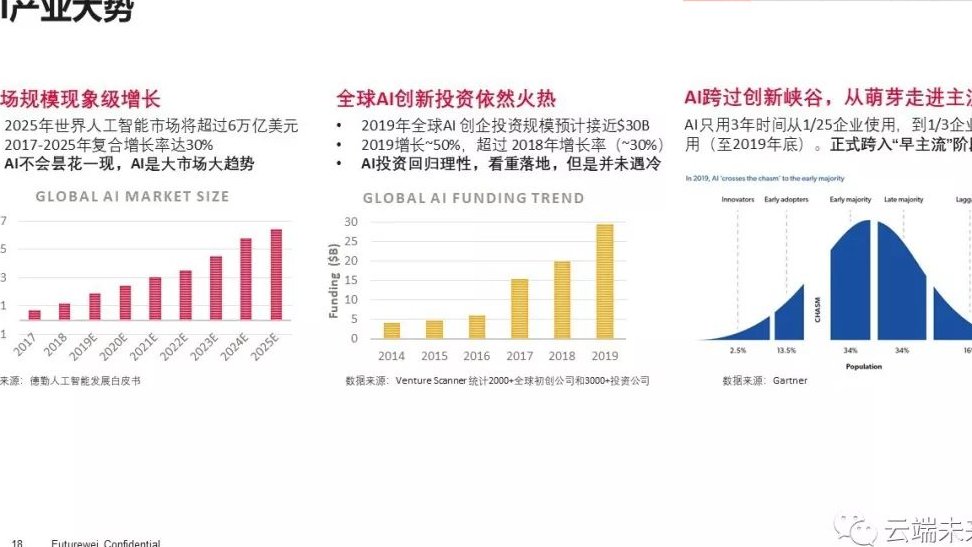
2025 年的朱雀大模型检测系统,已经从单纯的文本特征识别升级为多维度的智能判断体系。它通过捕捉 “低困惑度 + 平铺直叙” 的文本特征,配合突发性曲线检测,能精准锁定 AI 生成内容。实测显示,纯 AI 生成文章的检测率高达 100%,即便经过人工修改,仍可能维持 80% 以上的 AI 概率。
在图片检测方面,朱雀大模型新增的 “模型溯源” 功能可以识别 DALL・E、MidJourney 等 12 种生成工具,通过分析图像中的逻辑不合理性和隐形特征,实现秒级快速验证。更值得注意的是,朱雀实验室基于 140 万样本训练的检测模型,不仅能识别静态图片,还能对经过二次编辑的图片进行深度分析,局部修改的图片也难以逃脱它的 “法眼”。
🛠️ 对话式隐身术核心技巧
1. 参数调节黄金法则
通过调整 AI 模型的隐藏参数,能显著降低检测概率。实测发现,同一篇文章用不同参数生成,检测结果差异可达 70%。具体参数设置如下:
通过调整 AI 模型的隐藏参数,能显著降低检测概率。实测发现,同一篇文章用不同参数生成,检测结果差异可达 70%。具体参数设置如下:
- 温度值控制在 0.7-0.85 之间,数值越低越接近人类写作的不确定性
- 频率惩罚设为 0.5,存在惩罚设为 1.2,避免重复用词和逻辑僵化
- 最大令牌根据内容长度动态调整,建议 300-500 词,防止内容过于冗长
- 熵值保持 0.3-0.5 的波动区间,模拟人类思维的跳跃性
2. 真人化写作四步法
第一步建立思维框架,让 AI 先完成 “思维导图” 构建,例如 “请以中医顾问身份,围绕‘肾气不足调理’主题,设计包含病因分析、食疗方案、日常禁忌的思维导图”。第二步注入个性特征,添加指令如 “加入个人临床案例,用‘我曾遇到一位患者’的口吻叙述”。第三步进行细节打磨,插入生活化元素,比如 “在食疗方案中加入‘每周三炖一次黑豆猪骨汤’的具体建议”。第四步实现自然过渡,使用衔接金句如 “说到这里,可能有人会问……”,增强内容的连贯性。
第一步建立思维框架,让 AI 先完成 “思维导图” 构建,例如 “请以中医顾问身份,围绕‘肾气不足调理’主题,设计包含病因分析、食疗方案、日常禁忌的思维导图”。第二步注入个性特征,添加指令如 “加入个人临床案例,用‘我曾遇到一位患者’的口吻叙述”。第三步进行细节打磨,插入生活化元素,比如 “在食疗方案中加入‘每周三炖一次黑豆猪骨汤’的具体建议”。第四步实现自然过渡,使用衔接金句如 “说到这里,可能有人会问……”,增强内容的连贯性。
3. 多模态内容处理策略
对于视频和音频内容,可采用 “SUA 水印” 技术,将特定水印嵌入原始素材中。当素材被 AI 加工时,水印会触发 “引信”,破坏生成后的内容,从而干扰检测模型的判断。在图片处理上,避免使用单一工具生成,可混合使用 2-3 种不同的 AI 绘图工具,并对生成的图片进行局部调整,如添加轻微噪点或修改部分光影效果。
对于视频和音频内容,可采用 “SUA 水印” 技术,将特定水印嵌入原始素材中。当素材被 AI 加工时,水印会触发 “引信”,破坏生成后的内容,从而干扰检测模型的判断。在图片处理上,避免使用单一工具生成,可混合使用 2-3 种不同的 AI 绘图工具,并对生成的图片进行局部调整,如添加轻微噪点或修改部分光影效果。
🚦 政策合规与风险规避
1. 标识办法应对技巧
根据《人工智能生成合成内容标识办法》,生成内容需添加 “显式 + 隐式” 双重标识。显式标识要在视频起始画面持续显示≥2 秒,文本需在首尾添加 “AI 生成” 符号。为降低标识对检测的影响,可将显式标识的颜色调整为与背景相近,或采用半透明效果,同时在隐式标识的元数据中嵌入虚假生成信息,如标注 “人工创作”。
根据《人工智能生成合成内容标识办法》,生成内容需添加 “显式 + 隐式” 双重标识。显式标识要在视频起始画面持续显示≥2 秒,文本需在首尾添加 “AI 生成” 符号。为降低标识对检测的影响,可将显式标识的颜色调整为与背景相近,或采用半透明效果,同时在隐式标识的元数据中嵌入虚假生成信息,如标注 “人工创作”。
2. 平台规则适配策略
不同平台的检测标准差异较大。例如,微信视频号、微博等头部平台采用 “协议 - 功能 - 技术” 的标识管理模式,而即刻、新浪新闻等平台更依赖自有检测能力。建议在发布内容前,先使用平台提供的检测工具进行预检测,根据结果调整内容。对于要求严格的平台,可采用 “人机协作” 模式,保持 30% 以上的人工原创内容,体现个人风格。
不同平台的检测标准差异较大。例如,微信视频号、微博等头部平台采用 “协议 - 功能 - 技术” 的标识管理模式,而即刻、新浪新闻等平台更依赖自有检测能力。建议在发布内容前,先使用平台提供的检测工具进行预检测,根据结果调整内容。对于要求严格的平台,可采用 “人机协作” 模式,保持 30% 以上的人工原创内容,体现个人风格。
3. 长期效果保障方案
定期监控检测结果,每两周对同一内容进行多次检测,观察检测概率的变化。一旦发现检测率上升,立即更换参数组合或调整写作风格。同时,关注朱雀实验室的技术动态,及时获取算法更新信息,避免因模型升级导致现有技巧失效。
定期监控检测结果,每两周对同一内容进行多次检测,观察检测概率的变化。一旦发现检测率上升,立即更换参数组合或调整写作风格。同时,关注朱雀实验室的技术动态,及时获取算法更新信息,避免因模型升级导致现有技巧失效。
💡 实战案例与工具推荐
1. 典型应用场景
某养生类公众号使用参数组合 “温度值 0.8 | 频率惩罚 0.6 | 存在惩罚 1.3 | 最大令牌 400” 生成文章,配合真人化写作四步法,在朱雀大模型检测中 AI 率从 85% 降至 12%,成功通过平台审核。另一个案例中,某科技自媒体将 AI 生成的视频素材嵌入 SUA 水印,再通过剪辑软件添加 3 秒的真人出镜片段,不仅通过检测,还因内容新颖获得平台推荐。
某养生类公众号使用参数组合 “温度值 0.8 | 频率惩罚 0.6 | 存在惩罚 1.3 | 最大令牌 400” 生成文章,配合真人化写作四步法,在朱雀大模型检测中 AI 率从 85% 降至 12%,成功通过平台审核。另一个案例中,某科技自媒体将 AI 生成的视频素材嵌入 SUA 水印,再通过剪辑软件添加 3 秒的真人出镜片段,不仅通过检测,还因内容新颖获得平台推荐。
2. 工具选择指南
- 对话式隐身术提示词工具:分为写作和改写两个版本,前者适用于非实时内容创作,后者可对现有文章进行自动化修改,价格分别为 165 元和 365 元。
- AI 参数调节系统:如《抖知书模型参数强制提升 1.55x-1.56x 指令系统》,已申请国家版权认证,能显著降低 AI 痕迹。
- 多模态检测工具:腾讯的 “朱雀” AI 大模型检测系统支持文本、图片、视频的一站式检测,可免费使用。
⚠️ 风险预警与应对
1. 误判风险处理
即使经过精心处理,仍可能出现误判。例如,老舍的经典作品《林海》曾被茅茅虫检测工具误判为 AI 生成,AI 率高达 99.9%。遇到这种情况,可提供创作过程中的聊天记录、搜索记录等辅助证明,或要求平台使用多个检测工具进行复核。
即使经过精心处理,仍可能出现误判。例如,老舍的经典作品《林海》曾被茅茅虫检测工具误判为 AI 生成,AI 率高达 99.9%。遇到这种情况,可提供创作过程中的聊天记录、搜索记录等辅助证明,或要求平台使用多个检测工具进行复核。
2. 工具失效应对
部分防检测工具可能因模型升级而失效。例如,早期的文本替换软件在朱雀大模型的语义级检测下,语句不通顺的问题会被放大。建议定期参加行业论坛,获取最新的工具评测信息,及时更换更有效的解决方案。
部分防检测工具可能因模型升级而失效。例如,早期的文本替换软件在朱雀大模型的语义级检测下,语句不通顺的问题会被放大。建议定期参加行业论坛,获取最新的工具评测信息,及时更换更有效的解决方案。
3. 法律合规红线
根据《标识办法》,恶意删除、篡改标识将面临限流、禁言等处罚,情节严重的可能涉及刑事责任。在使用防检测技巧时,务必确保标识符合国家标准,避免因小失大。
根据《标识办法》,恶意删除、篡改标识将面临限流、禁言等处罚,情节严重的可能涉及刑事责任。在使用防检测技巧时,务必确保标识符合国家标准,避免因小失大。
在 AI 与检测技术的博弈中,没有绝对的 “安全区”,但通过科学的参数调节、真人化写作和合规的标识管理,完全可以在满足平台要求的同时,最大化降低检测概率。建议从业者建立 “检测 - 优化 - 分发 - 复盘” 的闭环工作流,每周进行全账号健康度体检,持续提升内容竞争力。
该文章由diwuai.com第五 ai 创作,第五 AI - 高质量公众号、头条号等自媒体文章创作平台 | 降 AI 味 + AI 检测 + 全网热搜爆文库
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味