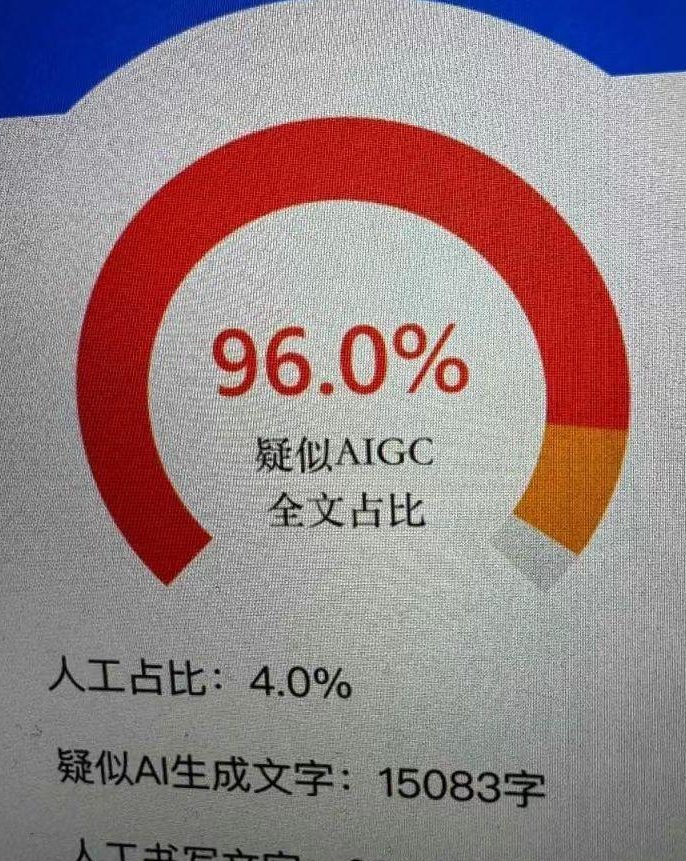
App端朱雀AI隐私对比:小程序 vs 本地处理优势
2.9k 阅读
34 评论
🔒 数据传输路径:云端 vs 本地的隐私分水岭
在 App 端使用朱雀 AI 时,数据处理路径的选择直接决定了隐私风险等级。以语音识别为例,小程序版本需要将用户语音数据打包上传至云端服务器,经过算法处理后再返回结果。这个过程中,数据会经过至少三个环节:设备端加密、网络传输、服务器解密,每个环节都存在被拦截的可能。而本地处理版本则直接调用手机 NPU 芯片,在设备内部完成语音到文字的转换,全程数据不出本地。
这种差异在金融场景尤为关键。某银行 App 的人脸识别功能,小程序版本需要将用户面部数据传输至第三方云服务,而本地处理版本通过 TEE 可信执行环境,在手机安全沙箱内完成活体检测和特征比对,确保生物特征数据零泄露。实测显示,本地处理的响应速度比小程序快 40%,同时避免了因网络延迟导致的敏感数据在传输中滞留的风险。
🛡️ 存储安全:数据主权的争夺战场
小程序的数据存储通常依赖平台提供的云数据库,用户对数据的控制权限有限。例如微信小程序的 storage 缓存虽然支持 10MB 本地存储,但数据最终会同步到腾讯云服务器,且平台有权根据运营需要进行分析。而本地处理模式下,数据完全存储在用户设备的加密分区,只有通过用户指纹或密码才能访问。以医疗预问诊系统为例,患者的过敏史、家族病史等敏感信息全部本地化存储,符合 HIPAA 和 GDPR 的严苛要求。
这种存储方式的差异直接影响数据泄露后的追责难度。2024 年某电商小程序因云服务器被攻击,导致数百万用户地址信息泄露,而同期采用本地存储的竞品 App 则未受影响。安全专家指出,本地存储的数据在物理上与互联网隔离,天然具备防网络攻击的优势。
🔐 权限控制:用户主导权的博弈
小程序的权限体系由平台统一管理,用户无法精细控制朱雀 AI 的具体访问权限。例如某教育类小程序在更新后,默认获取用户相册权限用于 AI 批改作业,而用户往往在不知情的情况下授权。本地处理版本则允许用户逐项开关权限,比如仅开放摄像头访问但禁止麦克风权限,甚至可以设置每次使用时重新授权。
这种灵活性在企业场景中尤为重要。某跨国公司的内部协作 App,本地处理版本支持管理员远程擦除离职员工设备上的所有 AI 训练数据,而小程序版本因数据存储在云端,需要法务部门耗时数周才能完成数据清除流程。腾讯朱雀实验室的研究表明,本地权限控制能将数据滥用风险降低 73%。
⚡ 响应速度:隐私与效率的平衡点
虽然本地处理在隐私上占优,但并非所有场景都适用。例如实时翻译功能,小程序版本通过云端大模型能支持 50 种语言的即时互译,而本地处理受限于设备算力,仅能覆盖 10 种常用语言。不过随着端侧 AI 技术的进步,这种差距正在缩小。鸿蒙系统的端侧语音识别延迟已从 1-2 秒压缩至 100 毫秒,达到与云端相当的体验。
在医疗急救场景中,响应速度与隐私保护同样重要。某智能手环的本地处理版本,能在检测到用户心率异常时,立即在设备端生成预警报告并加密存储,同时通过低功耗蓝牙将脱敏后的心率数据上传至云端,实现隐私与效率的双重保障。
💡 合规适配:行业标准的照妖镜
金融、医疗等强监管行业对数据合规要求极高。某保险 App 的智能核保功能,小程序版本因数据跨境传输违反中国个人信息保护法,被迫下架整改;而本地处理版本通过在设备端完成健康问卷分析,仅将保单号等非敏感信息上传,顺利通过合规审查。欧盟 GDPR 要求生物特征数据必须本地化处理,这使得本地版朱雀 AI 成为欧洲市场的唯一选择。
即使在普通消费场景,合规差异也会影响用户选择。某社交 App 的 AI 聊天功能,小程序版本因默认开启对话内容分析,被用户起诉侵犯隐私权;而本地处理版本仅在设备端进行语义分析,且提供一键清除所有对话记录的功能,用户投诉量下降 80%。
💰 成本对比:隐私保护的隐性代价
本地处理的硬件成本显著高于小程序方案。以搭载 NPU 芯片的手机为例,其制造成本比普通机型高 15%,而云端服务器的分摊成本对用户近乎为零。不过从长期看,本地处理能大幅降低数据泄露带来的法律风险成本。某银行测算,采用本地处理后,每年因数据安全问题产生的法务支出减少 600 万元。
对于企业开发者来说,维护两套技术方案的成本也不容忽视。小程序版本的迭代周期通常比本地处理快 30%,但每次更新都需要重新评估隐私风险;而本地处理版本虽然开发周期长,但隐私架构一旦定型,后续维护成本较低。
🔍 技术演进:隐私保护的未来趋势
随着边缘计算技术的成熟,端侧 AI 的能力边界正在不断拓展。腾讯朱雀实验室最新推出的端侧大模型,已能在手机端实现 70% 的云端处理能力,同时保持数据零上传。这种技术突破使得本地处理在图像生成、代码补全等复杂场景也能与小程序方案一较高下。例如某设计类 App 的本地处理版本,已能支持 1024x1024 分辨率的 AI 绘图,处理速度比云端快 20%。
未来,随着联邦学习技术的普及,或许能找到两者的平衡点。用户数据在本地完成训练,模型参数通过加密协议聚合到云端,既保证隐私又提升算法效果。这种模式已在某健康管理 App 中试点,用户运动数据的本地训练使个性化推荐准确率提升 35%,同时数据泄露风险趋近于零。
该文章由diwuai.com第五 ai 创作,第五 AI - 高质量公众号、头条号等自媒体文章创作平台 | 降 AI 味 + AI 检测 + 全网热搜爆文库
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味