朱雀AI检测误报率高的原因是什么?机制深度揭晓
2k 阅读
74 评论
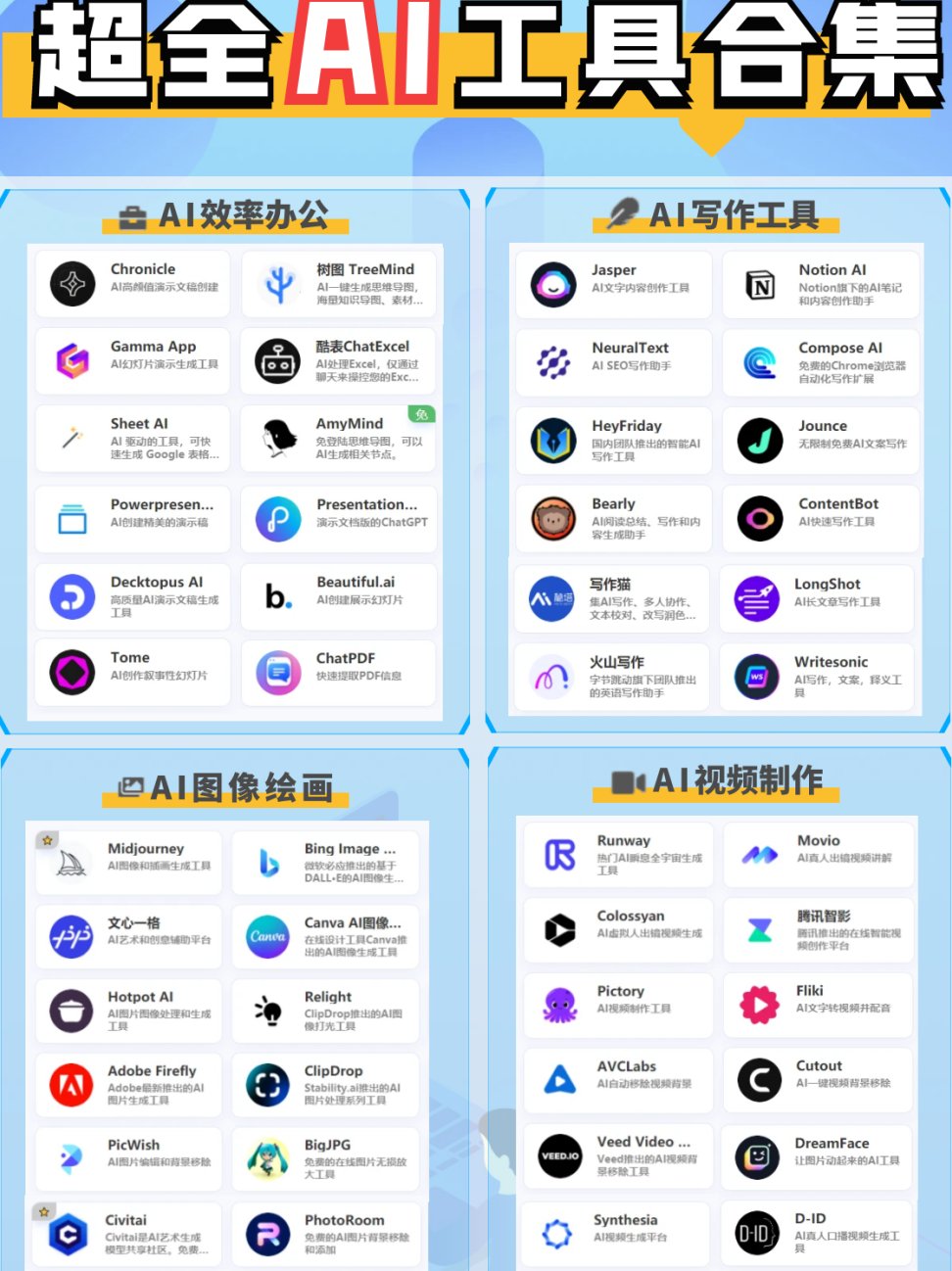
📊 训练数据的 “先天缺陷”
AI 检测工具的核心是通过对比样本特征来判断内容属性,朱雀 AI 检测的误报问题,首先得从它的 “学习材料”—— 训练数据说起。
如果训练数据里,人类原创文本和 AI 生成文本的界限没划清,麻烦就来了。比如有些数据集中混入了大量 “AI 辅助创作” 的内容,这些文本既带人类思维痕迹,又有 AI 工具的修饰特征。模型学的时候,就容易把这种混合特征当成纯 AI 文本的标志。后面遇到人类写的、风格稍微规整点的内容,比如精心打磨过的文案,就可能直接归到 AI 阵营里。
还有数据覆盖度的问题。要是训练数据里某类文本占比过高,比如网文小说多,学术论文少,模型对学术写作的特征就不敏感。用户上传一篇结构严谨的论文,模型可能因为它 “句式太规范”“术语密度高”,就误判成 AI 生成。这不是模型笨,是它没见过足够多的同类人类文本,只能拿有限的经验去套。
🔍 特征提取的 “表面化陷阱”
朱雀 AI 检测判断内容是否为 AI 生成,靠的是抓取文本里的 “特征信号”。但如果这些信号抓得太表面,误报率自然降不下来。
很多 AI 生成的文本确实有规律,比如喜欢用固定的过渡词、句式结构偏单一。但人类写作也可能出现类似特征。比如新手写文章,可能反复用 “首先”“然后”;专业领域的作者,为了严谨性会频繁使用术语,导致句式显得 “刻板”。朱雀要是把这些 “人类也可能犯的毛病” 当成 AI 专属特征,误报就不可避免。
更关键的是,它对 “语义逻辑” 的挖掘不够深。有些工具只看句子的 “形式”,不看内容的 “内涵”。比如一篇人类写的散文,可能因为段落切换快、意象跳跃大,被模型当成 “逻辑断裂的 AI 文本”。但实际上,这种跳跃正是人类灵感流动的表现。模型抓不住这种深层逻辑,只能被表面现象带偏。
⚖️ 阈值设置的 “失衡难题”
检测工具里有个隐形的 “天平”—— 判定阈值。这个数值定得好不好,直接影响误报率。
朱雀可能为了追求 “不放过任何 AI 文本”,把阈值调得太低。打个比方,就像安检时只要看到包里有金属就报警,哪怕是钥匙也不放过。结果就是,很多人类文本里只要有一点点像 AI 的特征,比如某个词的使用频率接近 AI 生成的均值,就被拉进 “嫌疑名单”。用户明明是自己写的内容,却反复被标红,就是这个原因。
而且不同场景下,合适的阈值其实不一样。给自媒体用的检测工具,和给学术机构用的,对 “严谨度” 的要求天差地别。但朱雀要是用一套固定的阈值应对所有场景,在对原创性要求高的场景里,比如投稿平台,就容易因为 “宁可错杀不可放过” 的策略,导致误报率飙升。
🌐 语言多样性的 “适配盲区”
人类语言的复杂程度,远超 AI 目前的理解范围。朱雀在面对不同风格、不同语种的文本时,很容易露出 “短板”。
拿中文来说,方言词汇、网络热梗、专业黑话层出不穷。比如 00 后常用的 “yyds”“绝绝子”,或者某个行业的特定缩写,模型可能没在训练数据里见过,就会觉得 “这不符合常规人类表达”,进而判定为 AI 生成。还有文言文、古诗词这类特殊文本,语法结构和现代文差异大,模型更容易 “看走眼”。
跨语种检测时问题更明显。如果朱雀的核心模型是基于英文训练的,适配中文时只是简单翻译特征库,就会水土不服。中文的 “意合” 特点(靠语义连接句子)和英文的 “形合”(靠关联词连接)差异显著,模型用英文的逻辑去套中文,误判率自然高。
📈 更新迭代的 “滞后性制约”
AI 生成工具一直在进化,今天的 AI 写出来的东西,可能和半年前的风格完全不同。朱雀要是跟不上这个速度,误报率就很难控制。
比如 ChatGPT 升级后,能模仿人类的 “口语化错误”,故意加一些重复词、语气词,让文本更像人类写的。但如果朱雀的检测特征还停留在 “AI 文本都很规整” 的阶段,就会把这些 “带瑕疵的人类风格 AI 文本” 当成真人类写的,同时把那些写得特别工整的人类文本当成 AI 的 —— 等于两头出错。
还有新出现的 AI 写作工具,可能用了全新的生成算法,比如基于 “知识图谱” 而非 “统计概率” 来生成内容。朱雀的模型如果没收录这种新算法的特征,面对这类文本时,要么漏检,要么为了覆盖未知风险,扩大判定范围,间接导致误报率上升。
🧩 场景迁移的 “水土不服”
同一个文本,在不同场景下的 “AI 特征” 可能完全不同。朱雀要是脱离具体场景去检测,很容易闹笑话。
比如朋友圈文案,人类写的时候可能东一句西一句,带很多表情符号和碎片化表达。但放到学术论文里,这种写法就很奇怪。要是朱雀用 “学术写作的标准” 去检测朋友圈内容,会觉得 “太混乱,像 AI 胡乱生成的”;反过来,用 “社交媒体标准” 去检测论文,又会觉得 “太规整,不像人类随手写的”。
还有内容长度的影响。短文本(比如一句话评论)的特征少,模型很难判断,这时候朱雀可能会默认 “特征不足 = AI 生成”;长文本里偶尔出现的 AI 风格段落,又可能被放大成 “整体为 AI 生成”。这种对不同长度、不同场景文本的 “一刀切” 处理,也是误报率高的重要原因。
【该文章由diwuai.com第五 ai 创作,第五 AI - 高质量公众号、头条号等自媒体文章创作平台 | 降 AI 味 + AI 检测 + 全网热搜爆文库
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味】
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味】