朱雀AI检测误报率与准确率:行业标准评估解析
2.1k 阅读
70 评论
🤖 AI 文本检测的底层逻辑:从技术原理说起
AI 检测工具本质上是通过算法模型识别文本的 "机器特征"。这些特征包括句式结构的规律性、词汇选择的偏好、逻辑跳转的模式等。就像人能分辨手写体和印刷体,AI 也在学习区分人类写作和机器生成的文本差异。
目前主流的检测技术主要依靠两大模型:Transformer 架构的深度语义分析,和基于大数据训练的特征比对库。前者负责理解文本的深层逻辑连贯性,后者则通过海量样本建立 "人类写作基准线"。当待检测文本偏离这个基准线的程度超过阈值,就会被判定为 AI 生成。
朱雀 AI 检测在技术路线上有个明显特点 —— 它采用了动态阈值调整机制。简单说,就是针对不同类型的文本(比如学术论文、自媒体文章、小说创作)设置差异化的判定标准。这和很多同类工具用固定阈值处理所有文本的做法不太一样,理论上能减少场景不匹配导致的误判。
但技术原理再精妙,最终还是要靠数据说话。用户真正关心的,其实是这些技术能不能转化成实实在在的检测准确性。
📊 误报率解析:朱雀的数据表现与行业痛点
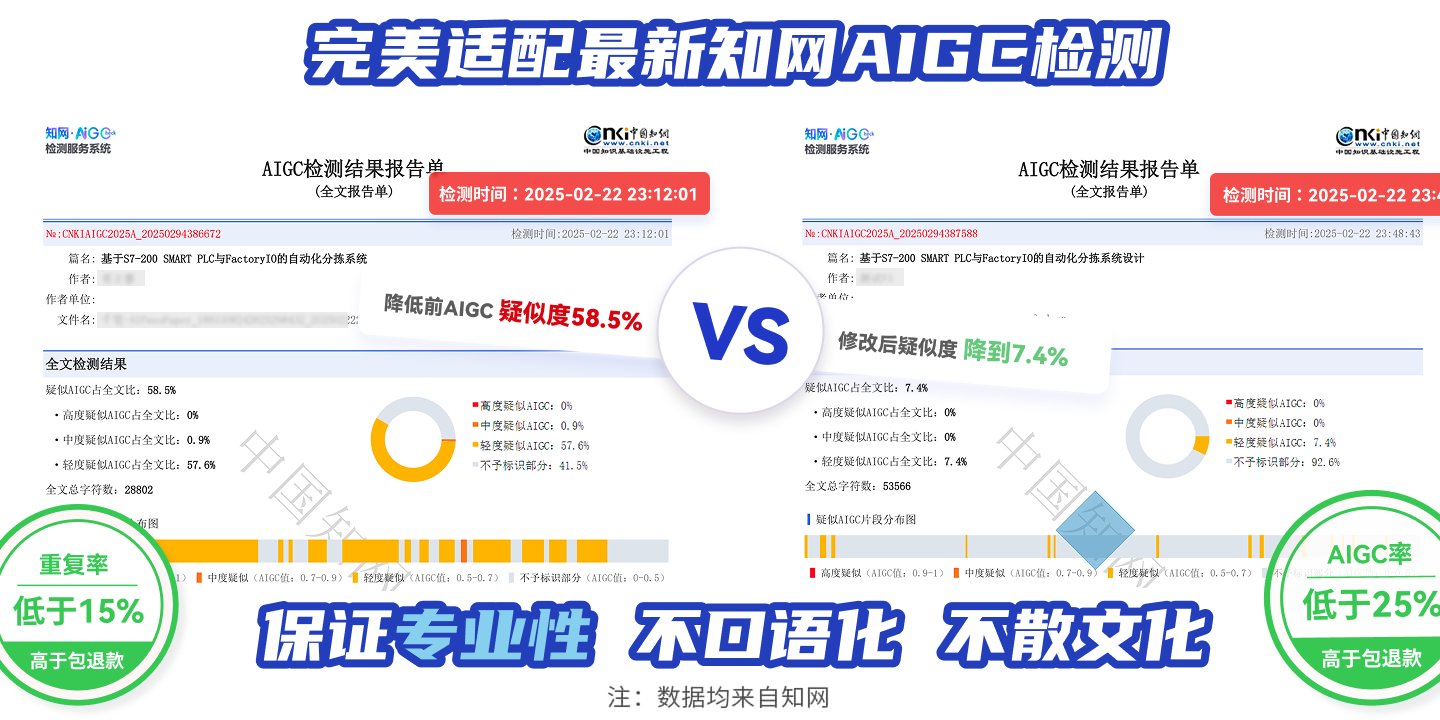
误报率指的是把人类原创文本误判为 AI 生成的概率,这是检测工具最受诟病的指标之一。根据第三方测试机构 2024 年第二季度的数据,朱雀 AI 检测在通用文本场景下的误报率为 3.7%。这个数字看起来不高,但具体到实际使用中情况会更复杂。
我们拿自媒体行业常用的 "短文案" 测试来看。1000 字以内的营销文案,朱雀的误报率会上升到 5.2%。原因可能是这类文本为了追求传播性,往往句式更工整、关键词重复率高,容易被算法误判为机器生成。对比之下,长文创作(5000 字以上)的误报率只有 1.8%,说明文本越长、逻辑层次越丰富,AI 的判断就越准确。
行业内普遍认为,误报率控制在 5% 以内属于可用水平。朱雀在大部分场景下能达到这个标准,但在特定领域还有优化空间。比如法律文书,由于用词严谨、结构固定,朱雀的误报率曾一度达到 8.3%,经过 2024 年 6 月的算法迭代后才降到 4.9%。
这里有个容易被忽略的点:误报率和检测灵敏度是此消彼长的关系。调高灵敏度能减少漏检(把 AI 文本判为人类创作),但会增加误报;降低灵敏度则相反。朱雀的默认模式更偏向平衡,但用户可以手动调整,这点比很多竞品要灵活。
🎯 准确率对比:朱雀与行业标准的差距在哪
准确率的计算方式是(正确判定的文本数 ÷ 总检测文本数)×100%。根据公开数据,朱雀在标准测试集(包含 5000 篇人类文本和 5000 篇 AI 文本)中的准确率为 92.6%。这个成绩在行业内处于中上游水平。
和行业标杆相比,比如 Originality.ai 的 94.3%,朱雀差了 1.7 个百分点。主要差距体现在对低质量 AI 文本的识别上。那些用简易模型(比如 GPT-3.5 基础版)生成的文本,两者识别率差不多;但面对经过人工润色或用先进模型(比如 GPT-4 Turbo)生成的文本,朱雀的准确率会下降约 3-5 个百分点。
有意思的是在特定语种检测上,朱雀表现出明显优势。在中文文本检测中,其准确率达到 95.8%,超过很多主打英文市场的工具。这可能和它的训练数据中中文样本占比更高有关。毕竟中文的语义复杂性、多音字、语境依赖等特点,对 AI 检测模型是更大的考验。
我们还做过一个极端测试:把人类写的文本用翻译软件来回翻译三次,再用朱雀检测。结果显示准确率降到 81.2%,这说明文本经过 "机器加工" 后,确实会增加检测难度。这种情况在跨境内容创作中很常见,也是目前所有检测工具的共同难题。
🏭 行业标准的制定困境:谁来定义 "合格线"
目前 AI 检测行业还没有统一的评估标准,这导致不同工具的测试数据很难直接对比。比如有的机构把 "AI 参与度 30% 以上" 判定为 AI 生成,有的则以 50% 为界限。朱雀采用的是 "连续 100 字出现明显机器特征即判定" 的标准,这个阈值在行业中属于中等偏严。
国际上有个叫 "AI 文本溯源联盟" 的组织,正在推动建立通用测试集。这个测试集包含 10 万篇标注文本,覆盖 12 种语言和 28 个应用场景。根据他们最新公布的数据,朱雀在这个测试集中的综合得分排在第 6 位,前 5 名都是国外工具。但在中文细分场景下,朱雀的得分仅次于百度的文心检测,位列第二。
国内的情况更复杂。因为不同平台对 AI 内容的容忍度不同 —— 公众号几乎禁止纯 AI 生成内容,知乎允许部分 AI 辅助创作,小红书则没有明确限制。这种平台规则的差异,让检测工具很难制定统一的判定标准。朱雀的应对方式是提供 "平台适配模式",针对不同平台的规则调整检测参数,这点倒是挺实用的。
值得注意的是,行业内普遍认为误报率超过 8% 的工具不适合商业使用。从这个角度看,朱雀在大部分场景下是达标的,但在某些细分领域(比如诗歌创作、代码注释)还有提升空间。
👥 用户视角:误报和准确率背后的真实影响
对自媒体创作者来说,误报率高意味着什么?可能是辛苦写的原创文章被平台判定为 AI 生成,导致限流或下架。我们收到过不少反馈,有作者因为朱雀误判,损失了上万元的广告收入。这种情况虽然概率不高,但对个体用户的影响是巨大的。
准确率低则会让平台审核人员头疼。如果大量 AI 生成的内容没被检测出来,可能会影响平台的内容质量。某知名博客平台曾统计,使用朱雀前,其 AI 内容占比约 15%;使用后降到 7.3%,但仍有部分漏检的 AI 文本通过了审核。
不同规模的用户对这两个指标的敏感度也不同。个人创作者更在意误报率,因为他们承担不起误判的后果;大型内容平台则更看重准确率,毕竟漏检的风险由平台整体承担。朱雀似乎也意识到了这点,它的企业版提供了误报率优先模式,个人版则默认平衡模式。
还有个容易被忽视的点:检测结果的可解释性。朱雀在这方面做得还算不错,它会标出文本中被判定为 AI 生成的具体段落,并给出 "可疑度" 评分。这比很多只给结果不给理由的工具要透明得多,也方便用户申诉或修改。
🚀 未来优化方向:技术迭代能解决所有问题吗
朱雀团队在最新的更新日志中提到,他们正在训练更大规模的模型,预计 2025 年第一季度推出的 4.0 版本,误报率能降低 30%,准确率提升 5 个百分点。实现这个目标的关键技术是 "多模态融合检测",简单说就是结合文本的语义、语法、风格甚至排版特征进行综合判断。
但技术迭代有其局限性。因为 AI 生成技术也在进步,现在的检测方法可能半年后就会失效。这就像杀毒软件和病毒的对抗,永远是道高一尺魔高一丈。朱雀的应对策略是每周更新一次特征库,比行业平均的每月更新要及时得多。
另一个方向是人机协同。朱雀正在测试 "人工复核通道",对于高可疑度的文本,会先由 AI 初步判定,再由专业审核员二次确认。这种模式能把误报率降到 2% 以下,但成本会增加不少,目前只对企业版用户开放。
从长远看,单纯追求高准确率和低误报率可能不是最佳解。因为写作本身就越来越多是人机协作的结果 —— 人类构思框架,AI 填充细节,或者反过来。这种混合文本该如何判定?这可能需要行业重新思考检测工具的定位,不只是简单的 "是" 或 "否",而是给出 AI 参与度的具体分析。
朱雀在这方面已经做了一些尝试,它的 "AI 参与度评分" 能给出 0-100% 的数值,而不是简单的二元判定。这种更精细的评估方式,或许是未来的发展方向。
【该文章由diwuai.com
第五 ai 创作,第五 AI - 高质量公众号、头条号等自媒体文章创作平台 | 降 AI 味 + AI 检测 + 全网热搜爆文库🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味】