朱雀AI检测误报率多少?实测数据+误判经典文学分析
5.8k 阅读
84 评论
🔍实测数据显示,朱雀 AI 检测的误报率在不同场景下差异较大。在南都大数据研究院的测试中,面对老舍经典文学作品《林海》,朱雀的 AI 检测率为 0 或趋近于 0,表现出色。然而,在检测人工撰写的某学科论文时,朱雀的 AI 检测率为 0,而茅茅虫、维普的误判率却超过九成。这说明朱雀在特定文本类型中准确性较高,但在其他场景下仍存在误判可能。
比如,有用户将《人民日报》的官方新闻稿上传至朱雀检测,结果显示 AI 生成概率为 100%。这可能是因为这类文本结构规范、专业术语多、行文工整,与 AI 生成内容的特征相似,导致检测工具误判。这种情况在学术论文中也较为常见,因为论文通常需要引用前人观点,注重强逻辑的行文构架,容易被误判为 AI 生成。
📚经典文学作品被误判的情况也值得关注。虽然朱雀在检测《林海》时表现准确,但其他工具曾出现误判《荷塘月色》《三体》片段的情况。以方文山为邓紫棋新书撰写的推荐语为例,第一次全文检测显示 AI 浓度 100%,提示 “易被多平台检测为 AI 生成”,但删除标题和方文山的名字后,检测结果显示 AI 浓度降至 37.05%,提示 “疑似 AI 辅助”。这表明检测结果可能受文本结构或特定词汇影响。
再比如,有网友将朱自清的《荷塘月色》与刘慈欣《流浪地球》的片段上传至某常用论文检测系统后,结果显示 AI 生成内容总体疑似度竟分别达到了 62.88% 和 52.88%。虽然这并非朱雀的检测结果,但也反映出 AI 检测工具对 “过于完美” 的文本存在误判风险。经典文学作品语言精炼、结构严谨,可能被系统误判为 “AI 生成”。
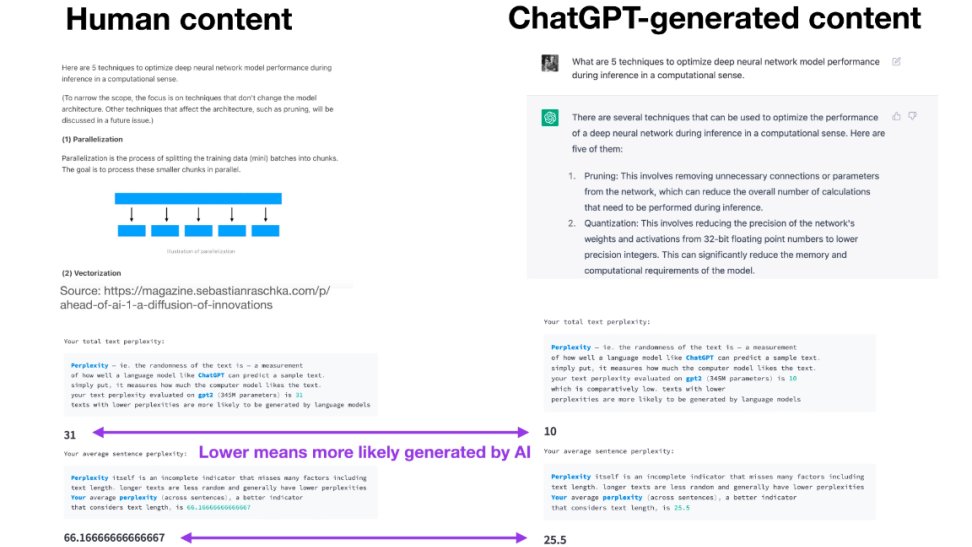
那么,为什么会出现这些误判呢?朱雀 AI 检测工具主要通过分析文本的困惑度(Perplexity)和爆发性(Burstiness)等维度来判断内容是否由 AI 生成。困惑度衡量文本的可预测性,AI 生成的文本通常语言模式更标准,困惑度较低;爆发性指句子长度和结构的变化,人类写作通常长短句结合,而 AI 生成的文本结构和长度较为均匀。因此,结构性强、专业术语多、行文规范的文本,如官方新闻稿、学术论文等,可能因语言模式工整、缺乏个人风格而被误判为 AI 生成。
对于用户来说,如何降低被误判的风险呢?腾讯官方建议,可以打乱句式节奏,交替使用长短句;加入个人化表达,如 “我觉得”“在我看来”;适当保留逻辑跳跃或不完美表达,避免文本过于规整或逻辑过于完美。此外,在检测前删除标题、作者信息等可能影响检测结果的元素,也能在一定程度上降低误判率。
需要注意的是,不同 AI 检测工具之间存在较大的判定偏差。例如,在检测方文山的推荐语时,朱雀的两次检测结果差异明显,而豆包 AI 则认为这篇文章不像是 AI 生成的。因此,用户在使用检测工具时,不应完全依赖单一工具的结果,而应结合多个工具进行综合判断。
总的来说,朱雀 AI 检测在大部分场景下表现可靠,但在面对结构规范、语言精炼的文本时,仍存在一定的误报率。用户在使用过程中,应充分了解其工作原理,采取相应的措施降低误判风险,同时结合人工审核,以确保检测结果的准确性。
该文章由diwuai.com第五 ai 创作,第五 AI - 高质量公众号、头条号等自媒体文章创作平台 | 降 AI 味 + AI 检测 + 全网热搜爆文库
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味