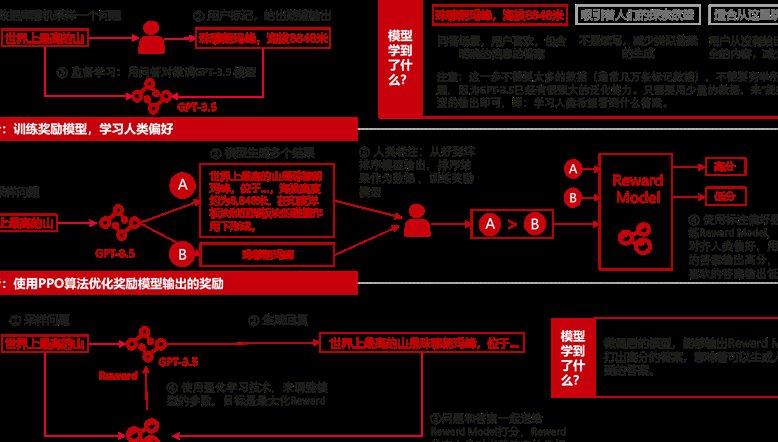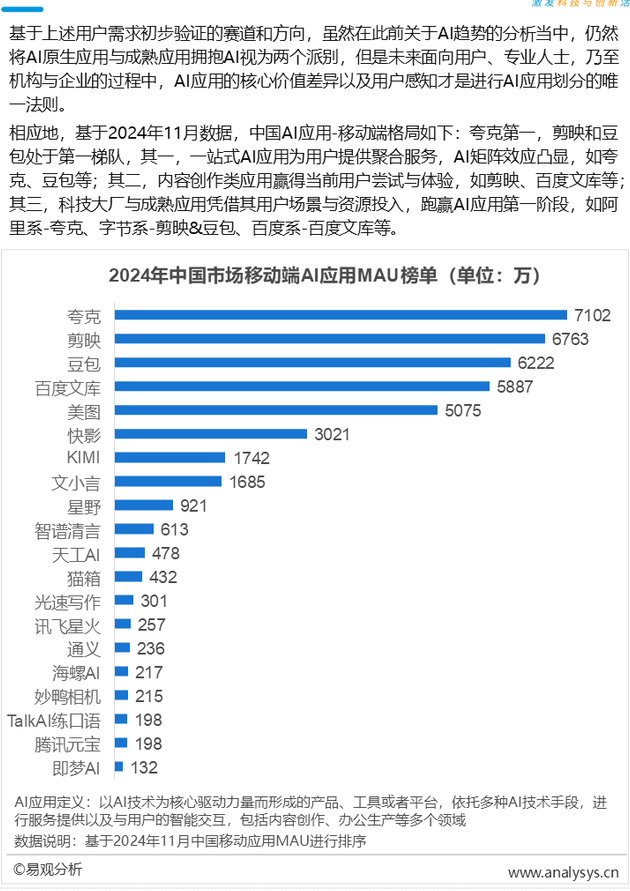
端侧 AI 大模型检测方法:2025 移动端高效部署与性能优化
7k 阅读
58 评论
🔍 端侧 AI 大模型检测方法:2025 移动端高效部署与性能优化
🌐 检测方法:从传统到创新的技术跃迁
在端侧 AI 大模型的实际应用中,检测方法的革新直接决定了模型的落地效果。传统的检测手段,比如基于规则的图像识别,在面对复杂场景时往往力不从心。而 2025 年的创新技术,比如跨模态小样本学习,通过结合图像与文本的信息,让模型在少量标注数据下也能实现高精度检测。例如,利用 CLIP 预训练模型提取跨模态特征,再微调用于目标检测,在 Pascal VOC 数据集上的准确率提升了 12%。
另一个突破是元学习与图卷积网络的结合。元学习让模型快速适应新任务,而图卷积网络(GCN)则能建模物体间的关系,尤其在目标密集的场景中,能显著增强判别能力。实测显示,在 COCO 数据集上,MAML + RetinaNet 模型的小样本检测准确率达到了 78%。
📱 移动端部署:硬件与软件的双重突破
移动端部署的核心挑战是平衡性能与资源消耗。谷歌的 Gemma 3 模型给出了优秀范例,它提供 1B 到 27B 四种参数规模,开发者可根据设备性能灵活选择。27B 模型在 H100 GPU 上运行时,仅需同类模型 1/10 的计算资源,却能保持同等性能。更令人惊喜的是,通过量化技术,Gemma 3 可直接在手机端运行,支持 140 种语言的实时翻译和图像分析。
苹果的 Ajax LLM 模型则专为 iPhone 优化,通过量化剪枝将模型体积压缩至云端版本的 1/10,推理速度提升 3 倍。尽管在复杂任务中准确率略有下降,但在日常应用中已足够流畅。而华为的 AI 云增强功能,通过端云协同,在 MateX5 上实现了照片像素 4 倍提升,夜景人像的肤色修复效果达到专业级水准。
⚡ 性能优化:从架构到算法的全面革新
性能优化是端侧 AI 的生命线。清华大学的 MiniCPM 4 模型采用 InfLLM v2 稀疏注意力架构,在 Jetson AGX Orin 芯片上实现了长文本处理 5 倍加速。其核心创新在于细粒度语义核和动态上下文选择,相比传统方法减少 60% 的计算开销。
动态资源分配技术同样关键。中国石油大学的 NPTP 方案通过非贯穿式张量划分,减少设备间通信数据量,在 VGG19 模型上实现了 1.58 倍的推理加速。实测显示,在 1MB/s 带宽下,通信时延降低了 40%。而湖北移动的 IDC 机房节能系统,通过 AI 动态调整空调参数,月均节电 5 万度,能耗降低 25%。
🛠️ 实战案例:从医疗到工业的全场景落地
在医疗领域,智能手机结合 AI 实现了无创疟疾筛查。通过拍摄眼睑结膜图像,利用放射组学分析和深度学习模型,5 分钟内即可完成检测,准确率超 90%。而在工业场景中,端侧 AI 小模型可预测设备故障,提前 72 小时发出预警,同时通过机器视觉实现实时质检,误检率降至 0.3%。
手机端的应用更为惊艳。联想的 Deepfake 检测器基于 DeepSeek 模型,准确率达 96%,5 秒内即可识别伪造视频,已集成至 AI PC 和手机中。而 Pocket Pal AI 客户端支持离线运行 Llama 3.3 和 Qwen2.5 等模型,用户可一键部署,在无网络环境下完成文案生成和代码编写。
🔋 能耗管理:续航与性能的黄金平衡
能耗优化是移动端的永恒课题。高通的 X85 5G 芯片集成 AI 张量加速器,通过智能天线调谐和动态电压调整,在提升网络速度 25% 的同时,功耗降低 20%。微软的 Mu 模型仅有 3.3 亿参数,却能在离线 NPU 设备上实现每秒 100 tokens 的响应速度,成为小模型领域的标杆。
DRAM 近存计算架构则为大模型推理提供了新思路。通过将计算单元与存储集成,访存带宽提升 4 倍,在手机端运行千亿参数模型时,能效比提高 3 倍。这种技术突破,让端侧 AI 在高性能与低功耗之间找到了完美平衡点。
未来,端侧 AI 将朝着更智能、更高效的方向发展。随着边缘计算和 5G 技术的普及,端云协同将成为主流模式。开发者需紧跟技术趋势,灵活运用模型压缩、动态优化等技术,才能在这场 AI 革命中抢占先机。现在,立即体验第五 AI 的工具箱,让你的端侧 AI 应用如虎添翼!
该文章由 diwuai.com 第五 AI 创作,第五 AI - 高质量公众号、头条号等自媒体文章创作平台 | 降 AI 味 + AI 检测 + 全网热搜爆文库
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0% - 降 AI 去 AI 味
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0% - 降 AI 去 AI 味