朱雀AI如何保障检测结果的公正性与准确性?技术架构揭秘
9.3k 阅读
70 评论
朱雀 AI 在检测结果的公正性与准确性上能有出色表现,背后的技术架构可是下了不少功夫。不是简单搭个模型就完事,从数据到算法,再到整个系统的设计,每一环都有讲究。
📊 数据层:用高质量 “食材” 打下靠谱基础
检测结果准不准,源头的训练数据很关键。朱雀 AI 的训练数据池做得相当扎实,覆盖范围特别广。你能想到的文本类型几乎都包含在内,像不同平台的自媒体文章、各种学科的学术论文、企业的商业文案,甚至还有学生的作文、网络小说这些。而且这些数据不是一次性收集完就完事,团队会定期补充新内容,确保能跟上文本创作的最新趋势。
更重要的是数据清洗环节,这一步直接关系到数据质量。系统会先自动扫描,把重复的文本去掉,避免数据冗余影响判断。然后人工团队会介入,逐批检查剩下的内容,像那些有错别字、逻辑混乱,或者明显带有偏见倾向的文本,都会被剔除。只有经过这样层层筛选的高质量数据,才能进入训练环节,这就从源头上保证了后续检测模型的 “口味” 不会被带偏。
另外,数据的多样性也被严格把控。比如同样是 AI 生成的文本,会收集不同 AI 工具、不同版本生成的内容;人类创作的文本,也会涵盖不同年龄、不同教育背景作者的作品。这样训练出来的模型,才不会对某一类文本特别 “敏感”,或者对某一类文本 “识别无能”,公正性自然就有了基础。
🔄 算法层:动态进化的 “火眼金睛”
光有好数据还不够,算法得能 “看懂” 这些数据才行。朱雀 AI 的核心算法采用了动态更新机制,这一点特别重要。现在 AI 生成工具更新太快了,今天能识别的特征,过两个月可能就不管用了。所以它的算法会实时跟踪市面上主流 AI 写作工具的变化,一旦发现新的生成特征,就会自动调整识别模型。
算法里还加入了多维度特征提取模块。不只是看文本的句式结构、用词习惯,还会分析逻辑连贯性、情感表达的自然度。比如人类写东西,偶尔会有重复或者小小的逻辑跳跃,这反而很正常;但 AI 生成的文本可能过于 “完美”,或者在某些细节上出现不符合人类思维的断层。这些细微的差别,算法都能捕捉到。
为了避免算法本身带有偏见,开发团队做了专门的防偏设计。在算法训练过程中,会引入 “反测试” 机制,故意输入带有不同倾向的文本,看模型会不会出现误判。如果发现某类文本的识别准确率明显偏低,就会针对性地优化算法参数,直到所有类型文本的识别标准保持一致。这种对算法偏见的零容忍,是保障公正性的核心。
🧪 模型训练层:多维度验证筑牢可靠性
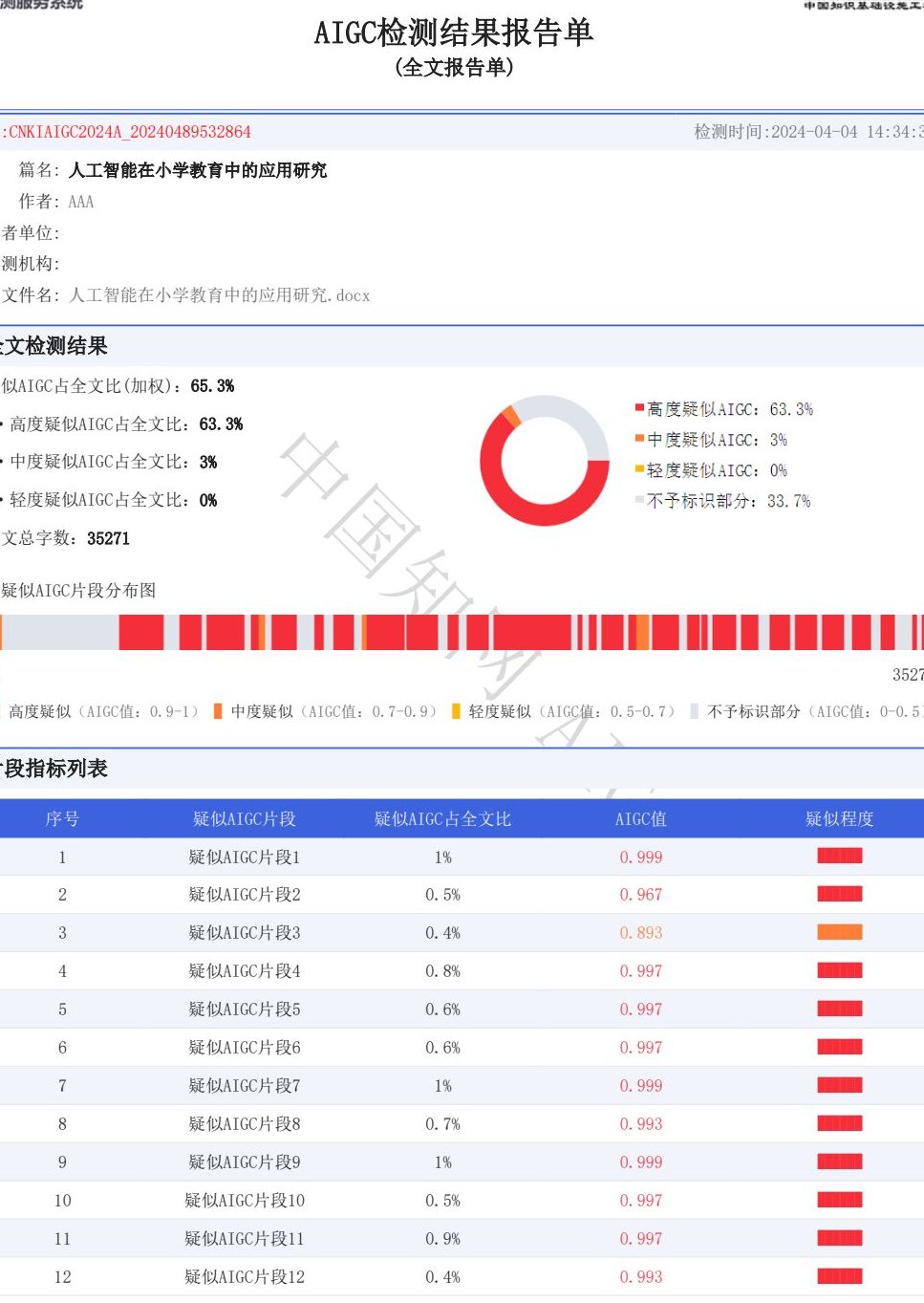
朱雀 AI 的模型训练不是闭门造车,而是采用了多维度验证体系。每次模型更新后,都会先在内部测试集上验证,这个测试集里既有已知的 AI 生成文本,也有人类原创文本,而且标注结果都是经过多人复核的。只有在内部测试的准确率达到 99% 以上,才会进入下一步。
接着会进行外部盲测,邀请不同行业的用户参与,比如自媒体作者、编辑、教师等,让他们提供自己的文本,不告知哪些是 AI 生成的,哪些是人类写的。模型检测完之后,再跟用户反馈的真实情况对比。这样做能发现一些内部测试集没覆盖到的边缘案例,比如某些小众领域的专业文本,或者带有特殊写作风格的内容。
模型还会进行压力测试,比如同时输入大量文本,看检测结果的稳定性;或者输入经过人工修改的 AI 文本,测试模型的抗干扰能力。有一次,测试人员把一篇 AI 生成的文章改得很像人类写的,故意加入几个常见的语法错误,结果模型还是准确识别出来了,因为它捕捉到了深层的逻辑结构依然带有 AI 的痕迹。这种严苛的测试,让模型的可靠性越来越强。
训练过程中还引入了 “对抗式学习”,简单说就是让模型和 “伪造者” 不断博弈。有专门的团队模拟各种 AI 生成文本的修改方式,试图 “骗过” 模型;而模型则在这个过程中不断学习,提升识别能力。就像警察和小偷的较量,小偷的手段越高明,警察的侦破能力也会跟着提升。
🏗️ 系统架构层:分布式处理 + 实时监控双保险
从系统架构来看,朱雀 AI 采用了分布式处理技术,这保证了检测结果的稳定性。不管同时有多少用户提交检测请求,每个文本都会被分配到独立的处理节点,不会因为负载过高而影响检测精度。而且每个节点的算法参数都是同步更新的,不存在不同节点标准不一的情况。
系统里还内置了实时监控模块,会记录每一次检测的详细数据,包括文本特征、检测过程、结果判定依据等。如果用户对检测结果有异议,可以申请查看详细的判定报告,里面会清晰地列出模型识别到的 AI 特征点。这种透明化的操作,让整个检测过程有据可查,也方便团队回溯可能出现的问题。
为了防止系统被恶意攻击,比如有人试图通过修改文本格式来干扰检测,架构上还加入了格式标准化处理。不管输入的文本是 Word 格式、PDF,还是纯文本,都会先转换成统一的格式,去除无关的排版信息,只保留文字内容本身。这样就避免了因格式差异导致的误判,确保所有文本在同一个起跑线上接受检测。
👥 外部监督机制:开放生态杜绝 “一言堂”
朱雀 AI 还建立了开放的外部监督机制,邀请行业专家、高校学者组成监督委员会。委员会会定期对检测结果进行抽样复查,一旦发现问题,就会提出整改建议。团队必须在规定时间内给出反馈和改进方案,这种外部压力让整个系统不敢有丝毫懈怠。
用户反馈通道也一直保持畅通,任何用户觉得检测结果有问题,都可以提交申诉。申诉会进入专门的审核流程,由人工团队重新检查,同时分析模型可能存在的漏洞。如果确实是模型的问题,不仅会纠正结果,还会把这个案例加入训练集,优化后续模型。
跟其他 AI 检测工具的对比测试也是常有的事。团队会选取同一批文本,用不同的工具进行检测,然后对比结果差异。如果发现朱雀 AI 在某些方面存在不足,就会针对性地改进。这种不闭门造车、主动接受外部检验的态度,让公正性有了更坚实的保障。
说到底,朱雀 AI 能保障检测结果的公正性和准确性,不是靠单一技术,而是整个技术架构协同作用的结果。从数据层的严格筛选,到算法层的动态进化,再到模型训练的多维度验证,还有系统架构的稳定支撑和外部监督的持续发力,每一环都缺一不可。
现在 AI 写作工具更新换代这么快,朱雀 AI 也得不断进化。但无论技术怎么变,保障检测结果的公正性和准确性,始终是它的核心目标。对于用户来说,能有这样一个靠谱的检测工具,不管是判断内容原创性,还是规范写作行为,都多了一份可靠的依据。
【该文章由diwuai.com
第五 ai 创作,第五 AI - 高质量公众号、头条号等自媒体文章创作平台 | 降 AI 味 + AI 检测 + 全网热搜爆文库🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 A