腾讯朱雀AI模型详解:它是如何区分人类创作与AI生成内容的?
2.9k 阅读
84 评论
🧠 朱雀 AI 的底层逻辑:不只是简单的文字比对
很多人以为 AI 检测工具就是拿文本和数据库里的 AI 生成内容做比对,其实完全不是这么回事。朱雀 AI 的核心逻辑是建立人类写作行为的数学模型,通过捕捉那些 AI 很难模仿的人类表达特征来做判断。
举个简单的例子,人类写东西的时候总会有 "口误式" 表达,比如重复某个词、突然切换句式,甚至出现无伤大雅的语法小错误。这些在 AI 生成内容里很少见,因为 AI 总是追求 "完美表达"。朱雀就是靠捕捉这种 "不完美" 来区分的。
它的底层是一个经过海量文本训练的 Transformer 模型,专门针对中文语境做了优化。训练数据里既有几千万篇人类原创内容,也涵盖了目前主流 AI 工具(比如 GPT、文心一言、Claude)的生成结果。通过对比这两类文本在特征上的差异,朱雀形成了一套独特的检测维度。
有意思的是,朱雀并不依赖单一特征下结论。比如有些人类作者本身就有很工整的写作习惯,单看句式规整度可能接近 AI,但结合用词多样性、情感波动曲线等其他维度,就能准确判断出这是人类创作。
🔍 文本特征拆解:朱雀关注的 7 个核心维度
想知道朱雀怎么工作,得先了解它到底看文本的哪些地方。根据公开的技术白皮书,它主要关注这几个维度:
词汇熵值是个很重要的指标。人类写作时词汇选择会有自然波动,同一个意思可能换好几种说法。AI 则倾向于重复使用某些 "安全词汇",导致词汇熵值偏低。朱雀会计算文本中词汇分布的随机性,熵值低于某个阈值就会被标记为可疑。
语义跳跃性也很关键。人类思考是发散的,写文章时可能从一个观点自然跳到相关联的另一个观点,中间甚至没有明显过渡。AI 生成的内容则更注重逻辑链的严密性,很少出现这种 "思维跳跃"。朱雀能识别这种跳跃是否符合人类认知习惯。
还有情感浓度曲线。人类表达情感时不会是均匀的,可能突然加重语气,也可能突然变得平淡。AI 的情感表达更像是 "匀速行驶",即使模仿强烈情感,也容易显得生硬。朱雀通过分析这种曲线的自然度来辅助判断。
另外像句式复杂度变化、高频词重复模式、标点符号使用习惯,甚至段落长度的随机波动,都是朱雀检测的重要依据。这些维度单独看可能都有误差,但组合起来就能形成很高的判断准确率。
📊 训练数据的秘密:覆盖 10 亿级中文文本样本
朱雀的厉害之处,很大程度上得益于它背后的训练数据规模。根据腾讯研究院公布的信息,朱雀的训练集包含了10 亿级别的中文文本样本,而且做了非常精细的分类。
这些样本不只是简单的文章集合,而是标注了明确的创作主体 —— 哪些是人类写的,哪些是 AI 生成的,甚至细分到是哪类 AI 工具生成的。这种标注精度让朱雀能准确捕捉不同创作主体的特征差异。
更重要的是,训练数据涵盖了几乎所有中文内容场景:从社交媒体的碎片化表达,到学术论文的严谨写作,再到小说的文学性描述。这种全面性让朱雀在检测不同类型文本时都能保持稳定表现。
腾讯还专门建立了 "对抗性训练" 机制。简单说,就是让朱雀不断接触最新的 AI 生成内容(包括用各种降 AI 味工具处理过的文本),逼着模型持续进化。这种动态更新机制,让朱雀能跟上 AI 生成技术的发展速度。
值得注意的是,训练数据里特别包含了大量 "跨语言干扰" 样本。比如先由 AI 生成英文再翻译成中文的文本,这类内容有独特的语言特征,朱雀对这类 "伪装者" 的识别准确率据说能达到 98% 以上。
💻 实际检测流程:从文本输入到结果输出的 5 个步骤
很多人用过朱雀的检测功能,但可能不知道背后的具体流程。其实从你把文本粘贴进去,到看到那个 "AI 概率值",中间经历了 5 个关键步骤:
第一步是文本预处理。朱雀会先把文本中的格式符号、特殊字符去掉,统一编码格式,确保后续分析不受这些因素干扰。同时会做断句、分词处理,把连续的文本拆分成有意义的语言单位。
第二步是特征提取。这一步会调用前面说的 7 大维度几十个子特征,对文本进行全面扫描。比如计算每个段落的平均句长、统计高频虚词的出现频率、分析情感词的分布密度等等。
第三步是异常点检测。系统会找出那些不符合人类写作习惯的 "异常特征"。比如某段话的句式突然变得极其规整,或者某个专业术语的使用频率远超人类正常水平,这些都会被标记为可疑点。
第四步是多模型交叉验证。朱雀不是靠单一模型下结论,而是同时启动 3 个独立训练的子模型进行检测,只有当 3 个模型的判断结果一致时,才会给出最终结论。这种设计大幅降低了误判率。
第五步是结果校准。系统会根据文本的类型(比如是新闻稿还是散文)、长度(短篇还是长篇)对结果进行微调。因为不同类型文本的 AI 特征表现会有差异,比如短篇文案的 AI 特征可能不如长篇明显。
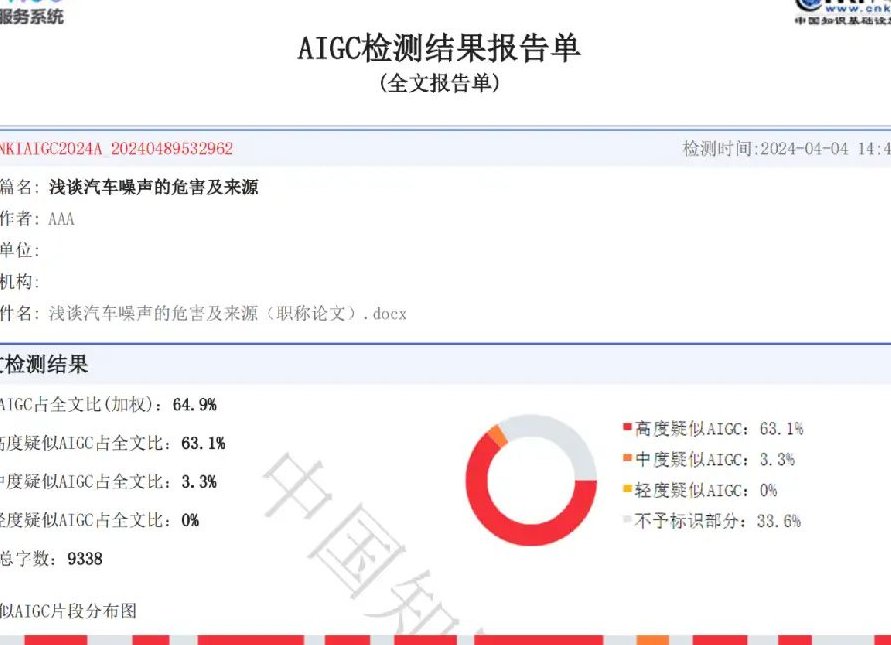
整个流程看起来复杂,但实际处理速度非常快。根据测试,检测一篇 1000 字的文章,从提交到出结果平均只要 0.8 秒,这种效率让它能轻松应对大规模内容审核场景。
📈 对内容创作的影响:倒逼创作者回归 "人性化表达"
朱雀这类 AI 检测工具的普及,正在悄悄改变内容创作的生态。最明显的变化是,那些靠 AI 批量生成 "伪原创" 内容的玩法越来越行不通了。
很多自媒体从业者发现,以前用 AI 生成文章,稍微改改就能通过平台审核,现在只要 AI 痕迹超过一定阈值,不仅推荐量会下降,严重的甚至会被限流。这逼着大家在 AI 辅助创作时,必须加入更多人类的独特思考。
教育领域的变化也很明显。高校已经开始用朱雀这类工具检测学生论文,特别是那些理论性不强、容易被 AI 替代的内容。这促使学生更注重原创观点的表达,而不是简单堆砌已有知识。
有意思的是,内容平台开始根据朱雀的检测结果调整推荐算法。那些 AI 概率值低的内容,更容易获得流量倾斜。这种机制正在引导创作者更注重 "人性化表达"—— 多用具体案例、个人体验、独特视角,这些都是 AI 很难模仿的。
当然也有争议。有些创作者觉得这种检测限制了创作自由,特别是那些本身就有工整写作习惯的人,他们的文章可能被误判为 AI 生成。不过从实际数据看,朱雀的整体误判率控制在 3% 以下,而且有完善的申诉机制。
🚀 未来进化方向:从 "检测" 到 "引导" 的角色转变
朱雀 AI 的迭代方向,已经不只是提高检测准确率那么简单了。从腾讯最近的技术动态来看,它正在向 "内容优化助手" 的角色转变。
一个重要的趋势是实时辅助创作。未来可能在你写作时,朱雀就能实时提示哪些段落的 AI 特征明显,建议你用更个性化的表达。这种 "边写边优化" 的模式,比写完再检测要高效得多。
另一个方向是细分场景定制化。比如针对小说创作,朱雀可能会弱化句式规整度的检测,更关注情节发展的自然度;针对学术写作,则会特别关注观点的原创性和论证的严密性。
多模态检测也是必然趋势。现在的朱雀主要针对文本,未来可能会扩展到图片、视频甚至音频内容,判断这些多媒体内容是否由 AI 生成。这需要跨模态的特征分析能力,技术难度不小。
最值得期待的是创作风格学习功能。据说腾讯正在开发让朱雀学习特定作者写作风格的功能,之后就能判断某篇文章是否符合该作者的一贯风格,这对打击 "AI 模仿名人写作" 可能会很有用。
不过技术发展总是攻防并进。随着朱雀的进化,新一代的 AI 生成工具也会针对性优化。这种技术博弈,最终可能会推动整个内容创作行业向更高质量的方向发展。
【该文章由diwuai.com第五 ai 创作,第五 AI - 高质量公众号、头条号等自媒体文章创作平台 | 降 AI 味 + AI 检测 + 全网热搜爆文库
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味】
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味】