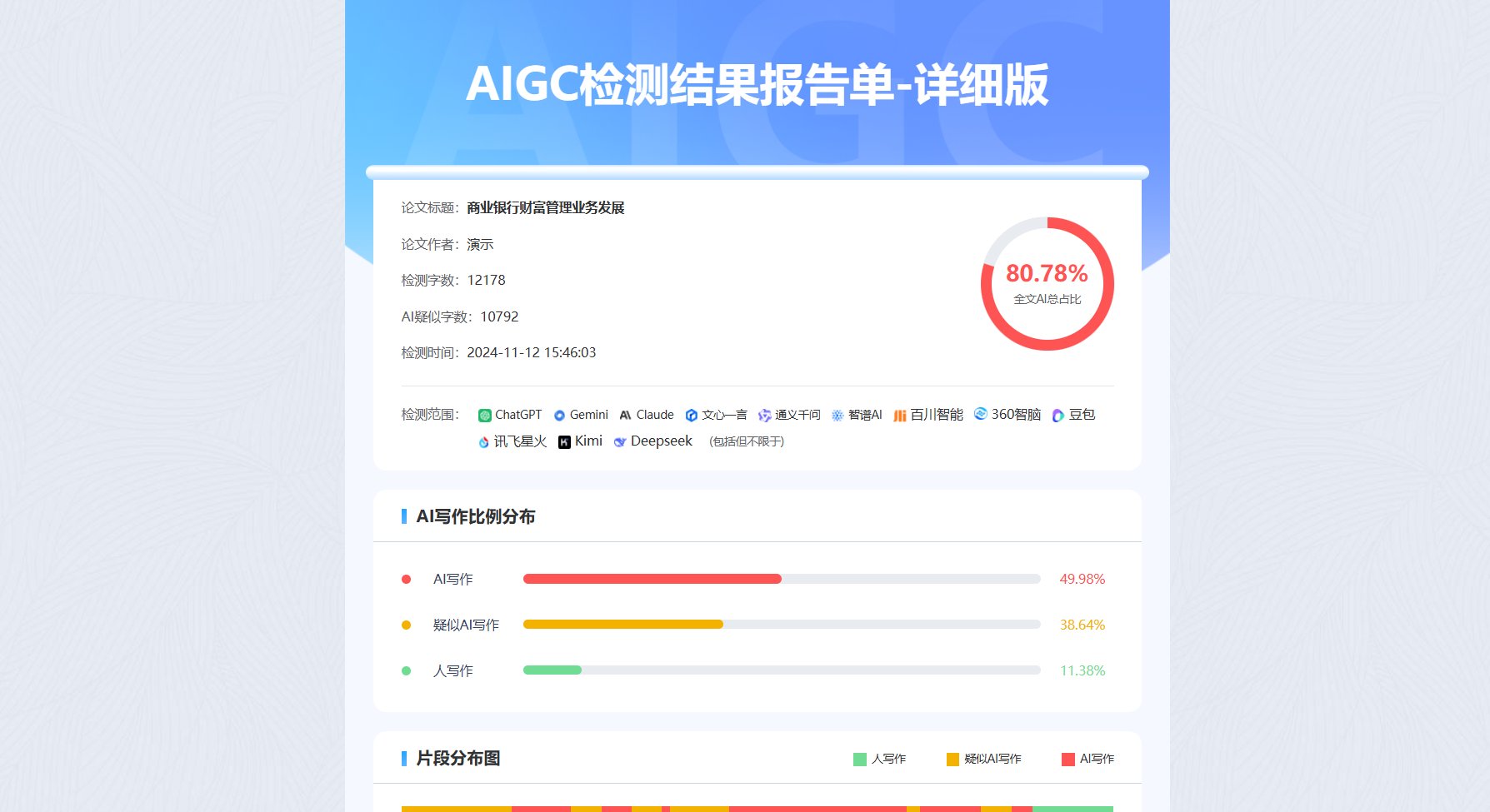
论文AIGC检测揭秘:哪个AI查重工具最严格且结果最准?
1.9k 阅读
42 评论
🔍检测算法大起底:不同工具的核心逻辑差异
当下市面上的 AI 查重工具,其检测算法主要分为三大类。第一类是基于训练的分类器,这类工具通过收集大量 AI 生成文本和人类写作内容进行模型训练,从而识别两者差异。比如知网 AIGC 检测,就是以其丰富的文献大数据资源为基础,结合独特算法来判断文本是否为 AI 生成。不过这类方法存在一个明显短板,训练数据覆盖范围有限,可能导致对特定领域或语言的文本识别不准确。
第二类是零样本检测器,无需大量数据训练,而是利用 AI 生成文本与人类写作在语言风格、句式结构等方面的固有差异进行检测。像西湖大学研发的 Fast-DetectGPT,通过条件概率曲率指标提升检测速度和准确率,相比 DetectGPT 速度提升 340 倍,准确率相对提升约 75%。这类工具的优势在于对新数据分布的适应性较强,但对未知源模型生成的文本检测效果可能不佳。
第三类是文本水印法,在 AI 生成内容时主动加入水印,通过技术手段检测。不过这种方法也有局限,水印可能被人为弱化或移除,且对于无法访问模型内部结构的大语言模型,可能无法成功加入水印。
不同工具在算法实现上也各有特色。例如,PaperPass 采用动态语义解析与跨库协同机制,将检测结果与知网的偏差率压缩至行业最低的 5% 以内。其基于 Transformer 架构的 Attention 机制,能够识别隐性逻辑关联,使概念抄袭检出率提升至 91%。而 MitataAI 检测器则采用混合检测模型,通过 n-gram 算法捕捉表面特征,再运用 BERT 模型解析语义连贯性,最后用对抗神经网络验证内容生成轨迹,这种三重验证机制使其在 AIGC 检测挑战赛中取得了 92.7% 的准确率。
📚数据库覆盖谁更强:学术资源与实时数据的较量
数据库是 AI 查重工具的 “弹药库”,其覆盖范围直接影响检测结果的准确性。知网作为国内最大的学术数据库,收录了海量的期刊、学位论文、会议论文等资源,与高校合作紧密,其检测结果在国内学术界认可度较高。但有学生反映,知网在 AIGC 检测方面不算太严格,可能存在漏检情况。
维普 AIGC 检测的数据库也较为全面,且在工程图纸识别和实验数据异常值检测方面有独特优势。其检测算法严格,对于字数较多的论文性价比更高。不过,有用户反馈维普检测系统更新后,同一篇论文的 AI 率可能出现大幅波动,从 0.84% 飙升至 41.3%。
国际工具如 Turnitin 国际版,主要覆盖英文文献,数据库更新周期为 15 天,在国际期刊中认可度高,英文内容检测精度达 98%。但其 AI 报告仅支持英文,价格较贵,12 元 / 千字符,且最大检测单词数在 1.5 万以内。iThenticate 则专注于期刊和出版领域的查重,与 Crossref Similarity Check 合作,检测结果与出版社一致,适合学术论文投稿。
值得注意的是,部分工具虽然数据库庞大,但对冷门资料和最新预印本的覆盖不足。例如,某民俗学论文引用地方志手抄本,简易系统因缺失专业库导致关键部分漏检率 17%。因此,对于涉及冷门领域或前沿课题的论文,建议选择支持自建库功能的工具,如 PaperPass,用户可上传本地文件补充检测范围。
⚖️实测对比:严格性与准确性的残酷现实
南方都市报的测评显示,不同工具在检测准确性上差异显著。对于老舍经典文学作品《林海》,知网、朱雀等 7 款工具能准确检测出 AI 率为 0 或趋近于 0,而茅茅虫的检测误判率高达 99.9%,万方将 1300 余字中的近 500 字标注为 “AI 生成”,误判比例达 35.6%。对于 AI 生成的散文《林海》,万方、朱雀准确识别出了 AI 生成内容(判定率 100%),而知网、挖错网、团象、PaperPass 却出现漏检,AI 率检测结果分别仅为 0%、0.1%、1%、2%。
在人工撰写的学科论文检测中,有 4 款工具(知网、朱雀、PaperYY、团象)的 AI 检测率为 0,茅茅虫、维普的检测误判率最高,均超过了九成。这表明,部分工具在识别真实文章时存在较大误判风险,可能导致学生被误伤。
国际工具方面,Turnitin 的误判率约 4%,而 OpenAI 的首款检测工具误判率高达 9%,在运行 6 个月后被迫终止。马里兰大学的研究分析了 12 种 AI 检测服务,发现平均有 6.8% 的概率把人写的文章当成 AI 生成的。这提示用户,即使是国际知名工具,也不能完全依赖其检测结果。
从检测速度来看,不同工具也有差异。MitataAI 检测器采用独创的并行计算技术,10 万字论文检测仅需 30 秒,比传统检测速度提升 300%。而知网 AIGC 检测完成一篇论文通常需要 5 分钟左右。
🚀AIGC 内容检测专项分析:模型特征与混合内容的挑战
AI 生成内容具有一些典型特征,如句式工整但缺乏灵活性、局部重复率高、信息熵低,常使用 “综上所述”“基于以上分析” 等模板化表达。检测工具正是通过捕捉这些特征来识别 AI 生成文本。例如,Fast-DetectGPT 通过分析文本的 “困惑度”,评估文本的流畅度,AI 生成内容通常逻辑过于完美、用词平滑,导致 “困惑度” 低。
然而,当 AI 生成内容经过二次编辑(如图片压缩、文本修改)后,检测技术可能难以提取有效的 “生成痕迹”。例如,将 AI 生成的文章进行同义词替换、段落重组等操作,可能降低检测工具的识别率。此外,混合内容(部分人工 + 部分 AI)的检测准确率也较低,知网对含 20% AI 内容的假新闻识别率偏低,而茅茅虫、PaperPass、万方的 AI 识别率过高。
对于多模态内容,如图文结合的论文,现有工具的检测能力有限。朱雀大模型检测和挖错网在图片检测中,对 AI 生成图的识别准确率较高,但对经 PS 修改的摄影图均被误判为 AI 生成,暴露出局部修改图片识别仍有难度。
🌟用户口碑与行业认可度:从学术机构到国际期刊
在国内,知网、维普、格子达是高校经常合作的三个学术检测网站。知网 AIGC 检测报告被全国 500 + 高校及科研机构认可,适合学位论文检测。维普 AIGC 检测的价格相对较低,38 元 / 篇,不论字数,适合字数较多的论文。朱雀大模型检测在实测中表现出较高的准确性和较低的误判率,逐渐获得用户认可。
国际期刊方面,65% 的国际期刊开始要求提交 AI 率证明。Turnitin 国际版和 iThenticate 在国际学术界认可度较高,适合英文论文投稿。例如,iThenticate 与 Crossref Similarity Check 合作,检测结果与出版社一致,能有效避免投稿时的重复率问题。
不过,部分高校对 AI 检测工具的可靠性存在疑虑。加州大学伯克利分校、Vanderbilt 和 Georgetown 都因可靠性问题,停用了 Turnitin 的 AI 检测功能。这些学校认为,过度依赖技术可能导致师生关系紧张,且检测工具无法完全替代教师对学生写作过程的了解。
🛠️如何选择最适合的工具:四大维度与实用建议
选择 AI 查重工具时,需综合考虑以下四个维度:
- 检测算法与准确性:优先选择采用先进算法(如 Transformer、零样本检测)且误判率低的工具。例如,朱雀大模型检测在实测中对 AI 生成内容的识别率较高,且对真实文章的误判较少。MitataAI 检测器的三重验证机制和可视化降重系统,能有效平衡检测准确性和用户体验。
- 数据库覆盖范围:根据论文类型和领域选择数据库全面的工具。如果是学术论文,知网、维普等国内工具更适合;如果是英文论文或投稿国际期刊,Turnitin 国际版、iThenticate 是更好的选择。对于涉及冷门资料或前沿课题的论文,可选择支持自建库功能的工具,如 PaperPass。
- 报告详细度与售后服务:优质工具应提供逐句分析、相似来源溯源和修改建议。例如,PaperPass 的报告用不同颜色标记重复段落,点击标红句子即可查看匹配文献,并给出改写示例。同时,良好的售后服务(如免费复检、人工客服)能帮助用户解决使用中的问题。
- 价格与使用场景:根据预算和需求选择。知网 AIGC 检测价格为 2 元 / 千字符,适合字数在一万字以内的毕业论文。维普 AIGC 检测 38 元 / 篇,适合字数较多的论文。Turnitin 国际版价格较高,12 元 / 千字符,适合英文论文检测。
在实际使用中,建议采取以下策略:初稿阶段用 MitataAI 或朱雀大模型检测进行基础筛查,定稿前使用知网 AIGC 检测模块复核,投稿时根据期刊要求补充 Turnitin 或 iThenticate 报告。对于检测结果存在争议的论文,可结合人工申诉、提供写作过程记录(如谷歌文档编辑历史)等方式自证清白。此外,注意避免过度依赖 AI 工具,在写作过程中保留人类特有的表达和思考,以降低误判风险。
该文章由diwuai.com第五 ai 创作,第五 AI - 高质量公众号、头条号等自媒体文章创作平台 | 降 AI 味 + AI 检测 + 全网热搜爆文库
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味