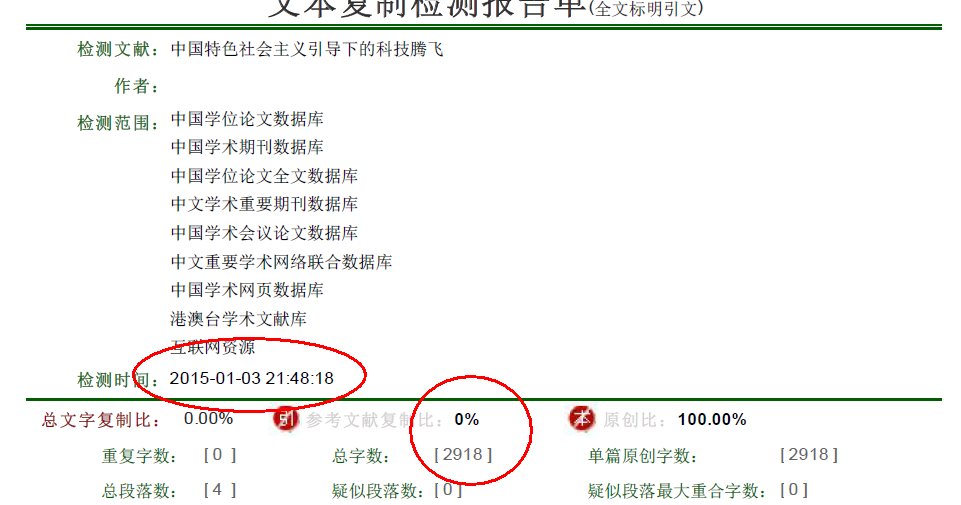
论文中的表格和代码参与查重吗?| 详解查重系统的检测范围
3.2k 阅读
29 评论
论文里的表格和代码到底会不会被查重?这问题困扰着不少毕业生。毕竟谁也不想因为这些细节影响论文通过率。今天就来好好聊聊这个话题,把查重系统对表格和代码的检测规则说清楚。
📊 表格在查重系统中的检测逻辑
表格算不算查重范围,得看表格里的内容类型。纯数据表格,比如实验数据记录表,只有数字和简单表头的那种,大部分查重系统不会重点检测。这是因为查重系统的核心是比对文字重复率,纯数字排列很难和其他文献完全重合。但要是表格里有大段文字描述,比如 “表 3-2 不同温度下的反应速率对比(数据来源:XXX 研究)”,这些文字部分会被拆分成字符串参与比对。
有些同学觉得表格是图片格式就安全了。其实不是这样。现在主流的查重系统,像知网 VIP5.3,已经能识别图片中的文字信息。去年就有学校出现过学生把表格转成图片,结果还是被标红的情况。原因是系统通过 OCR 技术提取了图片里的文字内容,和数据库进行了比对。
表格的结构设计也会影响查重结果。如果整篇论文的表格都是采用 “序号 + 标题 + 内容 + 备注” 的固定格式,而这种格式在同领域文献中很常见,系统可能会判定格式框架存在重复。这种重复虽然不会大幅拉高总文字复制比,但在 “段落抄袭” 维度可能会被标注。
💻 代码在查重中的特殊处理方式
代码查重的规则比表格更复杂。不同查重系统对代码的识别能力天差地别。知网目前对代码的检测还比较弱,主要针对 Java、Python 等主流编程语言的简单语句。但 Turnitin 的代码库已经收录了超过 2000 万段开源代码,能识别 C++、PHP 等 17 种编程语言的逻辑结构。
直接复制的代码片段肯定会被查出来。比如从 GitHub 上复制一段排序算法代码,不加修改就放进论文附录,重复率会高达 90% 以上。但有意思的是,代码中的注释部分比代码本身更容易被标红。因为注释多用自然语言编写,和数据库中的文字重合度更高。
有些同学会通过更改变量名、调整语句顺序来降重。这种方法对初级查重系统有效,但对付高级系统就没那么容易了。像 iThenticate 这样的系统,能通过抽象语法树分析代码逻辑,就算变量名改了,只要核心算法没变,还是会被判定为重复。
🔍 不同查重系统的检测范围差异
知网的检测范围有明确边界。它的数据库以中文期刊、学位论文为主,对英文文献的覆盖率只有 60% 左右。表格中的中文描述会被全面检测,但英文表格的重复率往往偏低。代码方面,知网只比对文字层面的相似度,不分析逻辑结构。
万方的特点是对表格的检测更严格。它会把表格中的数据和文字分开比对,即使数据相同但表述方式不同,也可能被标红。比如 “平均值为 5.6” 和 “均值 5.6”,在万方看来就是不同的表述,不会标红;但如果是 “表 5 实验结果统计” 和文献中的完全一致,就会被判定为重复。
维普的代码检测有个特殊之处。它会把代码转换成自然语言描述后再查重。比如一段循环代码,维普会先将其转换为 “通过 for 循环遍历数组元素” 这样的描述,再和数据库比对。这就导致有些看似不重复的代码,因为转换后的描述相似而被标红。
Turnitin 的国际版和 UK 版区别很大。国际版更侧重英文文献比对,对中文表格和代码的识别准确率只有 45% 左右。UK 版则专门优化了对工程类论文的检测,能识别 MATLAB 的.m 文件和 LaTeX 生成的表格。
📝 表格和代码的合理处理方式
处理表格时,数据呈现方式很重要。原始数据可以保留,但描述性文字一定要改写。比如把 “如表 2 所示,实验组的合格率高于对照组” 改成 “从表 2 可见,试验组合格比例较对照组更高”。同时,尽量采用三线表而非网格表,因为简洁的格式能减少和其他文献的结构重合。
代码降重有三个实用技巧。一是用伪代码代替真实代码,用自然语言描述算法流程;二是在代码中加入自己的注释,每 10 行代码至少添加 1 行原创注释;三是将长代码拆分成多个短片段,中间插入文字说明。这些方法能使代码重复率降低 50% 以上。
提交论文前最好做针对性检测。如果学校用知网,就别只靠万方检测结果来判断。可以先在 PaperPass 等初稿系统查一次,重点修改标红的表格文字和代码注释,最后再用学校指定的系统做终稿检测。
📌 学术规范与查重的深层关联
为什么表格和代码需要查重?因为这些内容同样属于学术成果的一部分。教育部 2022 年发布的《高等学校预防与处理学术不端行为办法》明确规定,抄袭包括 “窃取他人研究数据、程序代码等成果”。所以即使查重系统没检测出来,抄袭表格数据或代码仍然属于学术不端。
有些学科对表格的原创性要求更高。像经济学论文中的计量模型表格,必须是作者独立运算的结果;医学论文中的病例数据表格,需要提供原始数据来源证明。这些领域的期刊编辑部,会人工复核表格数据的真实性,不只是依赖查重系统。
代码的学术规范更严格。计算机学科的学位论文中,代码必须标注开源协议类型。比如采用 MIT 协议的代码,需要在论文中注明版权归属;使用 GPL 协议的代码,必须公开自己的修改部分。这些要求和查重系统无关,但直接影响论文能否通过答辩。
💡 实用降重技巧与避坑指南
处理表格的正确姿势是这样:数据可以引用,但呈现方式必须原创。比如参考文献中的表格用横向排列数据,你就改成纵向排列;原表格用百分比展示,你就换成绝对数值。同时,表格标题要加入自己的研究特征,比如 “基于 XX 算法的优化结果表” 比 “优化结果表” 更安全。
代码降重的进阶方法值得一试。把一段完整代码拆分成 “核心函数 + 调用示例” 两部分,中间插入算法流程图;用不同的编程范式实现同一功能,比如将面向过程的代码改成面向对象的;在关键步骤加入自定义函数,即使函数很简单也能有效降重。
别踩这些查重误区。以为图片格式的表格不会被查?现在 OCR 识别技术已经能处理 90% 以上的表格图片。觉得代码放在附录就安全?多数学校要求附录内容同样参与查重。还有人认为外文文献的表格不用改,其实 Turnitin 对多语言的识别能力正在快速提升。
了解清楚查重系统对表格和代码的检测规则,才能有针对性地做好论文写作。记住,降重的核心不是耍小聪明,而是通过自己的思考和再创作,让这些内容真正成为论文的有机组成部分。毕竟,学术诚信才是论文写作的根本。
【该文章由diwuai.com
第五 ai 创作,第五 AI - 高质量公众号、头条号等自媒体文章创作平台 | 降 AI 味 + AI 检测 + 全网热搜爆文库🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味】