朱雀大模型检测机制深度解读:如何防止数据泄露?
426 阅读
18 评论
🔍 朱雀大模型检测机制深度解读:如何防止数据泄露?
🛡️ 一、朱雀大模型检测机制的底层逻辑
朱雀大模型的检测系统核心在于多模态特征捕捉与动态行为分析。以图片检测为例,系统通过对比真实图片与 AI 生成图像的逻辑合理性和隐形特征差异,能在几秒钟内完成验证。比如,AI 生成的图片可能存在人体比例失调、光影逻辑矛盾等问题,这些细节都会被系统精准识别。
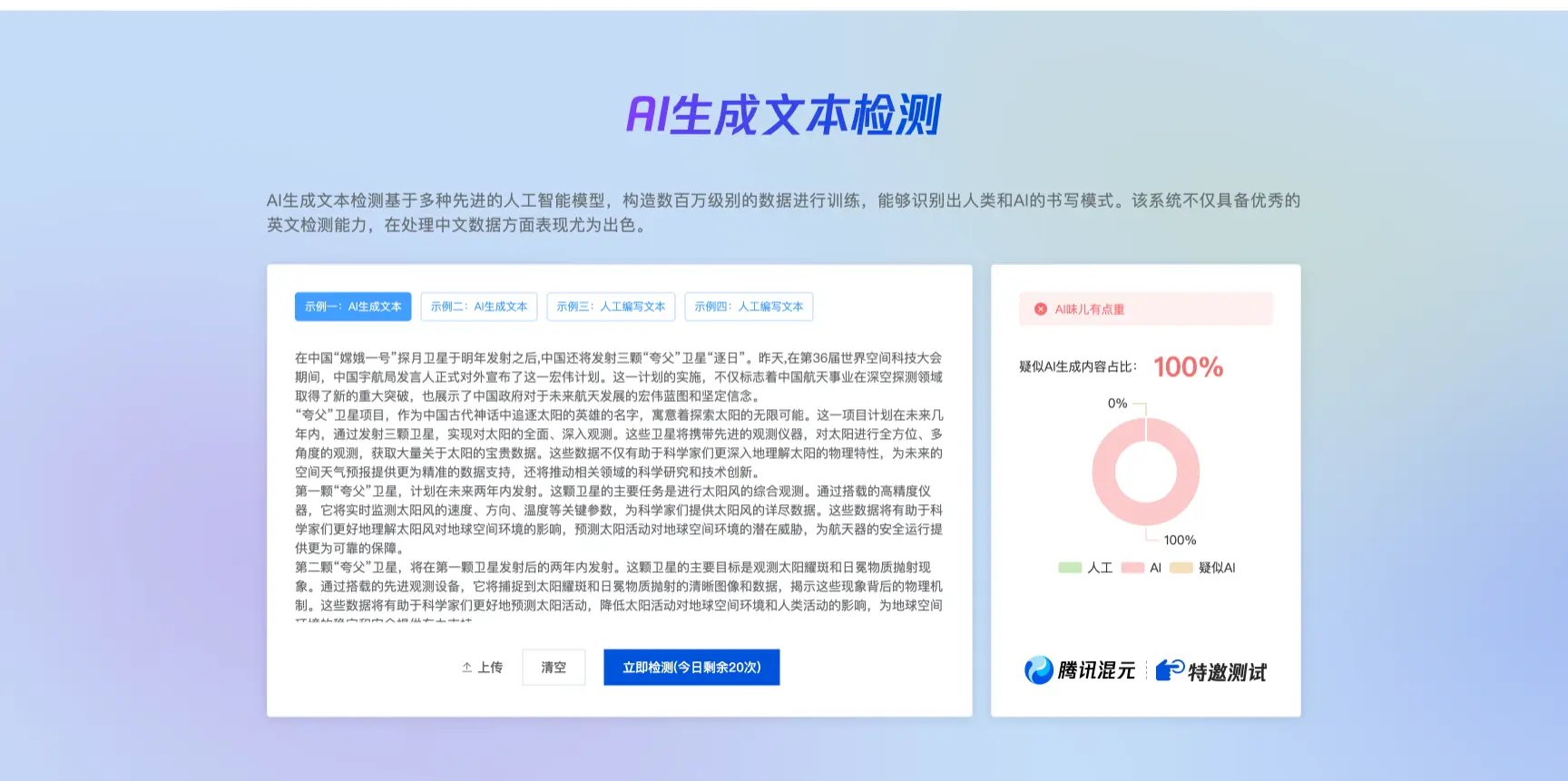
在文本检测方面,朱雀采用概率对比算法,通过分析文本与大模型预测内容的匹配度,推测其 AI 生成概率。值得注意的是,腾讯为提升准确性,在训练中使用了 140 万份正负样本,覆盖新闻、公文、小说等多种文体,甚至计划扩展至诗歌检测。这种多场景适配能力让朱雀在教育、媒体等对真实性要求高的领域尤为实用。
🔍 二、数据泄露的高危场景与攻击手法
大模型的数据泄露风险贯穿训练、推理、部署全流程。训练阶段,若数据采集未经授权或包含隐私信息,可能引发法律纠纷。比如,Meta 的 Llama 3.1 模型在发布前就因数据泄露导致商业利益受损。推理阶段,攻击者可通过提示词注入诱导模型泄露敏感信息,例如在客服场景中,特定触发词序列能绕过安全限制。
更隐蔽的是后门攻击,攻击者通过修改模型神经元或参数,在特定条件下触发恶意输出。腾讯朱雀实验室曾模拟实战攻击,发现只需控制少量神经元(精度损失约 2%),就能让模型在触发时错误分类图片。这种攻击方式几乎无感,传统防护手段难以察觉。
🛠️ 三、防止数据泄露的实战策略
1. 动态数据脱敏与访问控制
企业需建立多层次权限管理,根据用户角色和数据敏感级别分配访问权限。例如,金融行业可对客户信息实施实时语义遮蔽,确保在模型处理过程中敏感数据始终处于密态。火山引擎的大模型防火墙通过这一技术,将敏感数据泄露事件发生率降低 70%。
2. 智能威胁感知与响应
整合威胁情报与异常检测算法,构建 AI 安全运营中心(SOC)。例如,通过分析请求频率、内容特征,可识别出 API 滥用或 DDoS 攻击。朱雀实验室的检测系统能拦截包含恶意提示词的请求,并对异常流量实施熔断。
3. 模型全生命周期管理
- 训练阶段:严格审查数据来源,使用联邦学习或安全多方计算(SMPC)避免原始数据泄露。
- 部署阶段:采用容器化隔离和可信执行环境(TEE),防止模型参数被逆向解析。蚂蚁集团的 “隐语 Cloud” 平台通过 GPU 密态计算,使推理响应时间接近明文模型,同时保障数据安全。
- 退役阶段:彻底销毁模型文件,避免残留数据被恢复。
🌐 四、合规与生态协同
面对国际监管差异,企业需构建多区域合规框架。例如,欧盟《人工智能法案》将基础模型列为 “高风险应用”,要求强化透明度和可追溯性。朱雀大模型可通过日志审计系统记录全流程操作,满足合规审查需求。
行业合作同样关键。腾讯朱雀实验室与开源社区共享威胁情报,帮助开发者修复框架漏洞(如 vLLM 推理框架的安全隐患)。企业还应定期组织红蓝对抗演练,模拟提示词注入、模型越狱等场景,持续优化防御体系。
💡 五、未来趋势与建议
随着大模型技术迭代,检测与防护需向自动化、智能化演进。例如,朱雀实验室正在研发自适应水印技术,根据生成内容动态调整嵌入策略,提升抗篡改能力。企业应优先选用国产化技术栈,降低对海外框架的依赖,同时建立国产化替代路线图。
对个人用户而言,选择主流大模型(如豆包、通义千问)并交叉验证答案可信度,是降低风险的有效手段。若发现模型输出异常,及时反馈给服务商,推动算法优化。
结语
朱雀大模型的检测机制与数据防护是一场矛与盾的持续博弈。通过技术创新(如动态水印、零信任架构)、管理优化(全生命周期管控)和合规协同,企业可在释放大模型价值的同时,筑牢安全防线。正如火山引擎防火墙的实践所示,主动防御 + 智能响应才是应对数据泄露的核心策略。
朱雀大模型的检测机制与数据防护是一场矛与盾的持续博弈。通过技术创新(如动态水印、零信任架构)、管理优化(全生命周期管控)和合规协同,企业可在释放大模型价值的同时,筑牢安全防线。正如火山引擎防火墙的实践所示,主动防御 + 智能响应才是应对数据泄露的核心策略。
该文章由diwuai.com第五 ai 创作,第五 AI - 高质量公众号、头条号等自媒体文章创作平台 | 降 AI 味 + AI 检测 + 全网热搜爆文库
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味