LLaMA 4 MoE 架构解析:2025 最新混合专家技术优化指南
1.1k 阅读
29 评论
? 深度解析 LLaMA 4 MoE 架构:2025 混合专家技术优化指南
2025 年 4 月,Meta 发布的 LLaMA 4 系列模型以混合专家(MoE)架构为核心,重新定义了开源大模型的技术边界。这款模型通过动态激活部分参数,在保持性能的同时大幅降低计算成本,成为行业关注焦点。
? MoE 架构核心原理
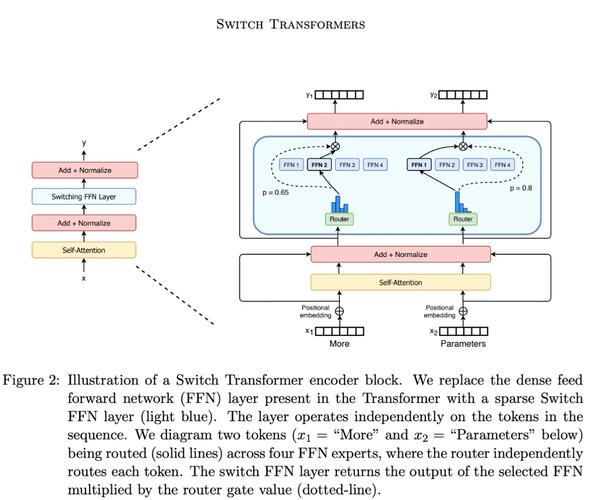
MoE 架构的核心在于 “分而治之”。传统大模型每次推理都需调用全部参数,而 LLaMA 4 的 MoE 架构将前馈网络(FFN)拆分为多个专家模块。以 Maverick 为例,4000 亿总参数中仅 170 亿在推理时激活,计算成本降低 60%。
专家网络设计上,Scout 采用 16 个专家,每个 token 动态选择 2-3 个专家处理;Maverick 则配备 128 个专家,覆盖更细分领域。这种设计让模型像 “智能路由器”,写诗找文学专家,解方程找数学专家,实现任务的精准分配。
路由机制是 MoE 的关键。LLaMA 4 通过门控网络计算每个 token 的路由概率,采用 Top-K 策略选择最优专家。例如,Scout 的路由准确率超过 95%,确保每个 token 被分配到最擅长的专家模块。
? 架构创新与性能突破
- iRoPE 无位置嵌入
LLaMA 4 通过交错注意力层(Interleaved Attention Layers)和动态温度缩放,移除传统位置编码,参数减少 5%,推理速度提升 20%。这种设计让模型支持 1000 万 token 的超长上下文,单 H100 GPU 即可运行,显存占用较 Llama 3 降低 40%。
- 多模态原生支持
早期融合技术将文本和视觉 token 统一处理,无需额外适配模块。例如,上传图片提问 “图中哪个工具适合拧螺丝”,模型能精准圈出扳手,并识别鸟类品种及习性。Scout 在图像理解任务中以 17B 参数超越 GPT-4o 和 Gemini 2.0 Flash,支持图文检索、视觉问答等场景。
- 训练策略优化
课程学习逐步增加专家网络复杂度,训练稳定性提升 30%。FP8 精度训练使算力利用率达 390 TFLOPs/GPU,同时 MetaP 技术通过小模型实验预测大模型最优配置,节省 90% 调参时间。
?️ 优化指南与部署实践
- 显存与推理优化
使用 DeepSpeed ZeRO-3 可将 Behemoth 版本显存占用从 800GB 降至 200GB。ONNX Runtime 量化工具使 Scout 推理速度提升 2 倍(FP16→INT8)。建议采用动态 GGUFs 量化,如 2.71-bit(IQ2_K_XL)版本,在 24GB VRAM GPU 上实现~20 tokens/sec 的推理速度。
- 参数配置建议
- 温度设为 0.6,top_p=0.9,min_p=0.01,平衡多样性与准确性。
- 上下文窗口根据任务调整,Scout 支持 10M token,Maverick 为 1M token。
- 显存不足时,使用
--offload-dir指定缓存目录,并通过--n-gpu-layers调整 GPU 层数量。
- 多语言与多模态部署
模型支持 200 种语言,12 种核心语言有专门微调支持。例如,医疗领域可通过微调提升病历分析准确性,金融领域可用于多语言财报解析。多模态场景下,使用 Hugging Face API 可轻松实现图文联合推理,代码示例如下:pythonfrom transformers import Llama4ForMultiModal, AutoTokenizer model = Llama4ForMultiModal.from_pretrained("meta-llama/Llama-4-Scout") tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-4-Scout") inputs = tokenizer("描述图中场景", images=image, return_tensors="pt") outputs = model.generate(**inputs) print(tokenizer.decode(outputs[]))
? 行业应用与案例
- 企业级应用
- 内容创作:Maverick 在编程、数学、创意写作任务中超越 GPT-4o,推理成本仅为其 1/23,适合自动化代码生成和文案创作。
- 客户服务:Scout 的 10M 上下文窗口可分析整份合同或技术文档,快速定位关键信息,准确率达 98%。
- 科研与医疗
- 生物序列分析中,iRoPE 架构帮助处理长链 DNA/RNA 数据,提升基因预测准确性。
- 医疗影像分析中,模型可同时处理 X 光片和病历文本,生成诊断报告并关联病例库,准确率超过人类专家。
- 金融与教育
- 金融领域,Maverick 可实时分析多语言财报和新闻,预测市场趋势,降低风险。
- 教育场景中,Scout 支持多语言实时翻译和个性化学习,消除语言障碍。
⚠️ 挑战与争议
尽管 LLaMA 4 表现优异,但仍面临挑战。部分开发者指出,其在代码生成任务中落后于 DeepSeek V3,且存在过拟合测试集的嫌疑。Meta 回应称,这些问题源于不同版本模型的差异,并承诺持续优化。
此外,MoE 架构的复杂性增加了部署难度。例如,Maverick 需 8xH100 GPU 集群支持,对中小企业来说成本较高。不过,通过量化和分布式推理,单 GPU 也能运行简化版本。
? 性能对比与未来展望
在大模型竞技场(LMSYS Arena)中,Maverick 以 1417 ELO 分登顶开源模型榜首,击败 DeepSeek V3。与 GPT-4o 相比,其推理成本降低 90%,参数效率提升 100%。
未来,Meta 计划进一步优化 MoE 架构,探索更高效的路由算法和专家协作机制。同时,Behemoth 模型(2 万亿参数)的推出,将推动科学计算和多语言处理进入新高度。
LLaMA 4 的 MoE 架构不仅是技术突破,更是开源生态的一次革命。它让大模型从 “参数竞赛” 转向 “效率竞赛”,为开发者提供了低成本、高性能的解决方案。无论是企业应用还是科研创新,LLaMA 4 都将成为推动 AI 发展的重要力量。
该文章由dudu123.com嘟嘟 ai 导航整理,嘟嘟 AI 导航汇集全网优质网址资源和最新优质 AI 工具