低困惑度和突发性检测指南:2025 最新标准下的 ChatGPT 内容识别技巧
666 阅读
33 评论
🔍 低困惑度内容的特征与检测要点
在 2025 年的 AI 内容检测标准下,低困惑度文本成了重点筛查对象。这类内容表面看起来自然流畅,实际是 AI 经过概率计算生成的 “安全表达”。比如医学论文中频繁出现的 “综上所述”“研究表明” 等套路化表述,看似严谨却缺乏人类写作的意外感。检测系统会分析文本的 “可预测性”,像 ChatGPT 生成的句子往往遵循最常见的词语搭配,比如 “首先、其次、此外” 这样的连接词使用频率远超人类。
这里有个关键指标叫困惑度(Perplexity),它衡量的是文本中词汇组合的意外程度。AI 生成的内容通常困惑度低,因为它会避开小众词汇和非常规表达。举个例子,人类可能会写 “这个方案有点野路子但效果惊人”,而 AI 更可能输出 “该方法具有创新性且成效显著”。检测工具会通过计算平均困惑度来判断,如果数值低于阈值,就可能触发警报。
突发性(Burstiness)也是重要依据。人类写作的句子长度和结构会自然变化,时而用短句强调重点,时而用长句展开论述。但 AI 倾向于保持均匀的节奏,比如连续使用复合句或并列结构。像某社交平台检测到的虚假笔记,其段落结构就像阅兵方阵一样整齐,缺乏真人写作的起伏感。
🚦 突发性内容的识别逻辑与实战方法
突发性检测关注的是文本风格的 “神经质程度”。人类在写作时会根据情绪和表达需求调整语气,比如科普博主讲解量子力学时可能突然插入一句 “这简直太酷了!”,这种跳跃性在 AI 生成内容中很少见。检测系统会分析文本的节奏变化,比如相邻句子的长度差异、标点符号的使用频率等。
实际操作中,突发性检测常与上下文分析结合。比如在医学论文中,AI 生成的患者描述可能过于标准化,缺乏具体细节和情感色彩。而人类撰写的内容会包含 “患者痛苦地蜷缩在病床上” 这样的具象化表达。某 MCN 机构测试发现,手持 DV 拍摄的街访视频因 “画面稳定性超出人类手持极限” 被误判,而 AI 生成的虚拟主播舞蹈却因风格稳定被放行,这说明突发性检测需结合多模态数据综合判断。
值得注意的是,突发性检测也存在误判风险。朱自清的《荷塘月色》曾被某系统检测出 “总体疑似度超过六成”,因为其优美的排比句和连贯的写景逻辑被误认为 AI 特征。这提示我们,检测结果需结合人工审核,不能完全依赖算法。
🛠️ 2025 年标准下的工具与技术升级
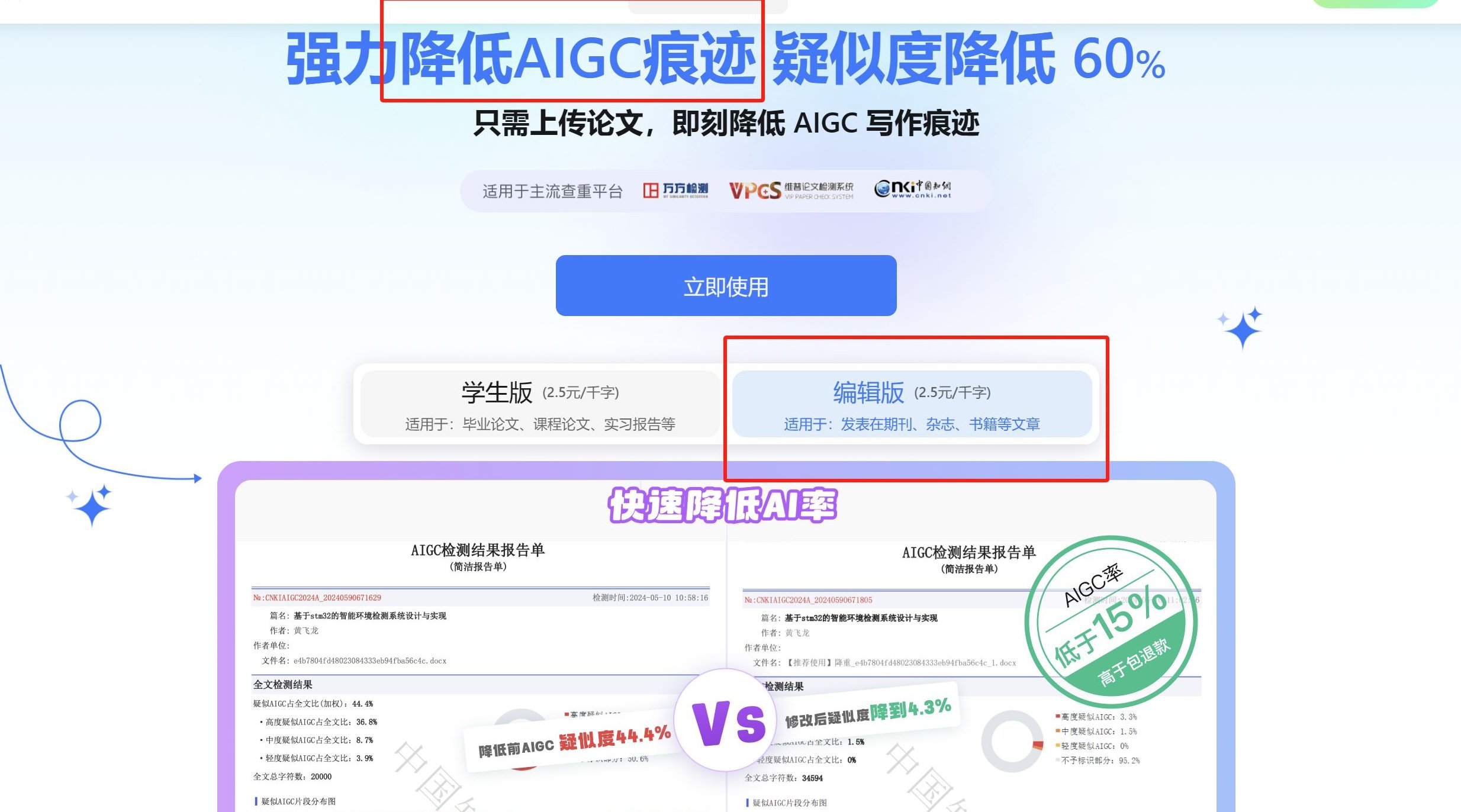
2025 年的检测工具在技术上有了显著突破。以 DETECTAIGC 为例,它不仅能识别 ChatGPT、文心一言等主流模型,还新增了对知网、维普、万方的检测结果预测功能。用户上传论文后,系统会同步生成多平台的 AI 率预估报告,帮助提前规避风险。此外,工具还支持句子级别的标注,用红、橙、紫三色区分高度、中度、轻度疑似段落,方便针对性修改。
复旦等机构研发的 ImBD 框架则从 “模仿” 角度切入。通过学习 AI 的写作风格特征,如特定词汇偏好和句式结构,系统能更精准地识别机器修订文本。实验表明,该方法在检测 GPT-4 修改的内容时,准确率提升了 19.68%,且仅需 1000 个样本和 5 分钟训练就能超越商业工具。
不过,工具的选择需根据场景灵活调整。比如学术论文更适合使用 SciDetect,它能识别医学术语的使用习惯;而社交平台内容则需结合反检测提示词,像在 Reddit 回复中加入 “卧槽”“绝了” 等口语化表达,通过增加困惑度绕过算法拦截。
📊 数据驱动的分析框架构建
要提升检测效果,需建立数据驱动的分析框架。首先,收集不同场景下的 AI 生成文本和人类原创内容,构建训练集。比如某平台在 2025 年上半年处理了 60 万篇 AI 生成的虚假笔记,这些数据可用于优化识别模型。其次,引入多维度特征,除了困惑度和突发性,还需考虑情感倾向、专业术语密度等指标。
在实际应用中,可采用分层检测策略。第一层通过快速扫描识别明显的 AI 特征,如公式化结构和高频连接词;第二层进行深度语义分析,检查逻辑连贯性和上下文一致性。某高校的测试显示,这种方法能将误判率降低 40%。
此外,数据标注需注意多样性。某平台的检测系统因训练集 90% 来自欧美创作者,导致亚裔创作者的方言节奏被误判为 “非人类”,这提示我们要确保数据覆盖不同文化背景和语言习惯。
⚠️ 常见误区与应对策略
误区一:查重率低 = AI 率低。传统查重工具检测的是内容重复度,而 AI 检测关注的是生成痕迹。比如直接翻译外文 AI 内容可能查重率为零,但因句式结构和用词习惯仍会被判定为机器生成。
误区二:人工修改后就安全。某医学期刊发现,作者用 AI 生成方法学部分后人工润色,仍被 Turnitin AI 识别出来,因为其论证逻辑和术语使用仍带有 AI 特征。正确做法是在 AI 辅助后进行深度重构,比如补充实际案例、调整论述角度。
误区三:依赖单一工具。不同检测系统的算法差异可能导致结果不一致。比如某论文在 DETECTAIGC 中显示 AI 率 15%,在 GPTZero 中却高达 30%。这时需结合多平台报告和人工审核综合判断。
应对策略方面,可采用 “工具 + 人工” 双保险模式。先用 DETECTAIGC 等工具定位高风险段落,再通过人工逐句修改,比如将 “研究表明该方法有效” 改为 “通过 30 组对照实验数据验证,此方案在实际应用中展现出显著可行性”。同时,合理使用提示词引导 AI 生成更自然的内容,比如在指令中加入 “使用口语化表达”“加入个人观点” 等要求。
该文章由diwuai.com第五 ai 创作,第五 AI - 高质量公众号、头条号等自媒体文章创作平台 | 降 AI 味 + AI 检测 + 全网热搜爆文库
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味