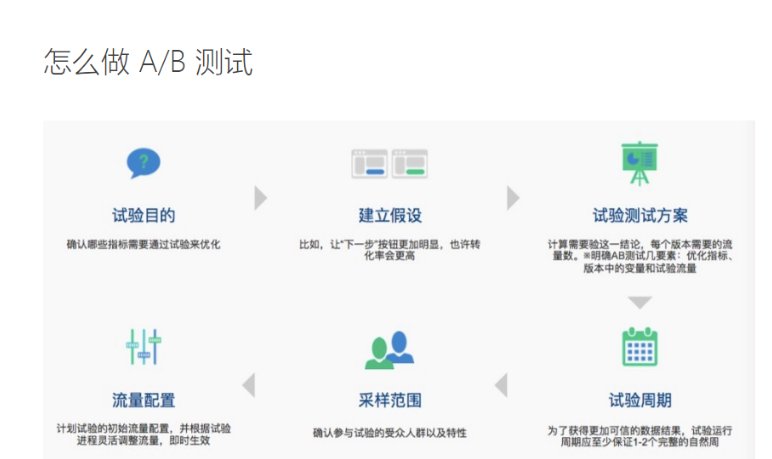
通义智文与豆包对比:AI 工具选择指南 2025
1.5k 阅读
36 评论
在 AI 工具爆发的 2025 年,通义智文和豆包作为国产大模型的代表,凭借差异化的技术路线和场景化能力,成为个人创作者、企业用户和开发者的热门选择。这两款工具究竟谁更适合你的需求?接下来从核心功能、技术架构、价格体系到实战场景,带你深度拆解这场 AI 工具的终极对决。
? 核心功能大比拼:从文本到多模态的能力鸿沟
通义智文:专业领域的硬核担当
通义智文在长文本处理上展现出碾压级优势。其最新发布的 QwenLong-L1-32B 模型支持 13 万 token 的超长上下文,相当于能同时处理 300 页 A4 纸的内容。无论是分析法律合同中的复杂条款,还是整合数十篇学术论文生成文献综述,通义智文都能通过动态推理模式,在快速响应和深度分析之间灵活切换。在金融领域,它能精准识别财务报告中的风险点;在科研场景,可自动提炼论文核心结论并生成参考文献。
通义智文在长文本处理上展现出碾压级优势。其最新发布的 QwenLong-L1-32B 模型支持 13 万 token 的超长上下文,相当于能同时处理 300 页 A4 纸的内容。无论是分析法律合同中的复杂条款,还是整合数十篇学术论文生成文献综述,通义智文都能通过动态推理模式,在快速响应和深度分析之间灵活切换。在金融领域,它能精准识别财务报告中的风险点;在科研场景,可自动提炼论文核心结论并生成参考文献。
多语言支持方面,通义 APP 已覆盖 119 种语言和方言的互译,同传翻译功能不限时免费开放,分屏对照、逐句对照等交互模式满足会议、旅游等多场景需求。其翻译质量在专业术语处理和上下文语义一致性上表现突出,尤其适合跨国企业的文档协作。
豆包:创意场景的全能选手
豆包的多模态能力堪称一绝。超级创意 1.0 功能支持 2K 高清文生图,中英文字符排版准确率达 98%,输入 “春节促销海报,中国龙元素,金色立体字‘福满人间’” 即可生成印刷级设计稿。动态记忆复活术更是将老照片修复升级为动态视频生成,上传泛黄全家福并描述 “祖母笑着挥手”,AI 能捕捉微表情生成 10 秒动态影像。
豆包的多模态能力堪称一绝。超级创意 1.0 功能支持 2K 高清文生图,中英文字符排版准确率达 98%,输入 “春节促销海报,中国龙元素,金色立体字‘福满人间’” 即可生成印刷级设计稿。动态记忆复活术更是将老照片修复升级为动态视频生成,上传泛黄全家福并描述 “祖母笑着挥手”,AI 能捕捉微表情生成 10 秒动态影像。
在交互体验上,豆包的语音通话和屏幕共享功能重新定义了人机协作。实时语音大模型支持英语陪练、故事讲述等场景,视频通话中可基于真实场景进行问答互动,学生能直接拍摄题目获取解题思路,科研人员可分析论文图表。屏幕共享功能覆盖文档处理、软件操作辅助等 12 类场景,让远程协作的 “在场感” 大幅提升。
? 技术架构解析:MoE 与长上下文的博弈
通义智文:长上下文推理的王者
通义智文的技术壁垒集中在长上下文处理上。QwenLong-L1-32B 模型通过强化学习优化,实现了从短上下文到长上下文推理能力的无缝迁移,在数学、逻辑和多跳推理任务中逼近 Anthropic 的 Claude-3.7-Sonnet-Thinking。其独创的 CPRS 框架通过多粒度上下文压缩,无需依赖 RAG 检索即可处理复杂文档,在企业级知识库构建和跨文档推理中表现优异。
通义智文的技术壁垒集中在长上下文处理上。QwenLong-L1-32B 模型通过强化学习优化,实现了从短上下文到长上下文推理能力的无缝迁移,在数学、逻辑和多跳推理任务中逼近 Anthropic 的 Claude-3.7-Sonnet-Thinking。其独创的 CPRS 框架通过多粒度上下文压缩,无需依赖 RAG 检索即可处理复杂文档,在企业级知识库构建和跨文档推理中表现优异。
豆包:MoE 架构的效率革命
豆包 1.5 Pro 采用稀疏 MoE 架构,性能杠杆达到 7 倍,激活参数仅为稠密模型的 1/7,却能达到世界一流模型的性能。这种设计使其在处理短视频脚本生成、电商文案创作等高频场景时,既保证了生成质量又大幅降低了推理成本。豆包的多模态能力得益于字节跳动自主研发的火山芯片,推理速度较 GPT-4 Turbo 快 3 倍,为实时交互提供了硬件保障。
豆包 1.5 Pro 采用稀疏 MoE 架构,性能杠杆达到 7 倍,激活参数仅为稠密模型的 1/7,却能达到世界一流模型的性能。这种设计使其在处理短视频脚本生成、电商文案创作等高频场景时,既保证了生成质量又大幅降低了推理成本。豆包的多模态能力得益于字节跳动自主研发的火山芯片,推理速度较 GPT-4 Turbo 快 3 倍,为实时交互提供了硬件保障。
? 价格体系对比:从个人到企业的成本权衡
通义智文:企业级应用的性价比之选
通义千问主力模型 Qwen-Long 的调用价格降至 0.0005 元 / 千 tokens,较行业平均水平低 97%。对于需要处理大规模文档的企业,通义智文的长上下文能力可减少分段处理的时间成本,尤其适合金融、法律等对文本分析深度要求高的行业。其按实际使用量计费的模式,避免了企业为冗余功能付费。
通义千问主力模型 Qwen-Long 的调用价格降至 0.0005 元 / 千 tokens,较行业平均水平低 97%。对于需要处理大规模文档的企业,通义智文的长上下文能力可减少分段处理的时间成本,尤其适合金融、法律等对文本分析深度要求高的行业。其按实际使用量计费的模式,避免了企业为冗余功能付费。
豆包:个人创作者的普惠选择
豆包的基础功能完全免费,新用户可获 7 天高级功能试用。个人专业版月费约 10-50 元,按年订阅更优惠,适合学生、自媒体人等预算有限的用户。企业端,豆包通过区间定价模式,将 80% 的请求导向 0-32K 主力需求区间,综合成本较竞品下降 62.9%,特别适合电商、教育等需要高频调用 AI 服务的行业。
豆包的基础功能完全免费,新用户可获 7 天高级功能试用。个人专业版月费约 10-50 元,按年订阅更优惠,适合学生、自媒体人等预算有限的用户。企业端,豆包通过区间定价模式,将 80% 的请求导向 0-32K 主力需求区间,综合成本较竞品下降 62.9%,特别适合电商、教育等需要高频调用 AI 服务的行业。
? 实战场景指南:选对工具让效率翻倍
学术研究与专业写作
- 写论文时,豆包能快速生成逻辑框架和论据,但在专业术语的深度理解上稍显不足。通义智文则能精准分析文献中的数据图表,生成符合学术规范的综述。
- 翻译外文资料时,通义 APP 的 119 种语言支持和专业术语处理能力更胜一筹,而豆包的实时语音翻译在跨国交流中更便捷。
创意内容生产
- 制作短视频脚本,豆包的热点捕捉和多风格生成能力可快速产出爆款内容。通义智文在长视频文案的结构梳理上更具优势。
- 设计海报时,豆包的文生图功能能直接生成印刷级素材,通义智文则擅长数据可视化,适合制作报告中的图表。
企业级应用
- 处理合同、财务报告等长文档,通义智文的 13 万 token 上下文和动态推理模式能大幅提升分析效率。
- 搭建智能客服系统,豆包的实时语音交互和多轮对话能力更贴合用户需求,且调用成本仅为行业 1/150。
? 终极决策建议:根据需求锁定最优解
- 选通义智文:如果你需要处理超长文档、进行专业领域翻译或搭建企业级知识库,通义智文的长上下文能力和多语言支持是不二之选。
- 选豆包:如果你是内容创作者、学生或需要高频交互的企业用户,豆包的多模态功能和普惠定价能带来更高的性价比。
- 小孩子才做选择:两者结合使用效果更佳。用通义智文处理专业文档,用豆包生成创意内容,让 AI 工具真正成为你的 “左膀右臂”。
在 AI 工具的选择上,没有绝对的好坏,只有是否适合。通义智文和豆包分别代表了专业深度和创意广度的两个极端,根据自身需求合理搭配,才能最大化 AI 的价值。无论是学术研究、商业创作还是企业管理,找到最适合的工具,才能在智能时代的竞争中抢占先机。
该文章由dudu123.com嘟嘟 ai 导航整理,嘟嘟 AI 导航汇集全网优质网址资源和最新优质 AI 工具。