2025最新AI率降重操作,朱雀检测误判案例与反AI文本解析
5.4k 阅读
14 评论
在 2025 年的内容创作领域,AI 检测与反检测的博弈愈发激烈。随着朱雀等检测工具的普及,许多创作者发现,即便原创内容也可能被误判为 AI 生成,这给学术写作、自媒体运营等场景带来了巨大挑战。本文将结合最新案例,深入解析朱雀检测的误判逻辑,并分享一套行之有效的降重策略,帮助你在 2025 年轻松应对 AI 检测。
🚫 朱雀检测误判:经典作品为何 “中枪”?
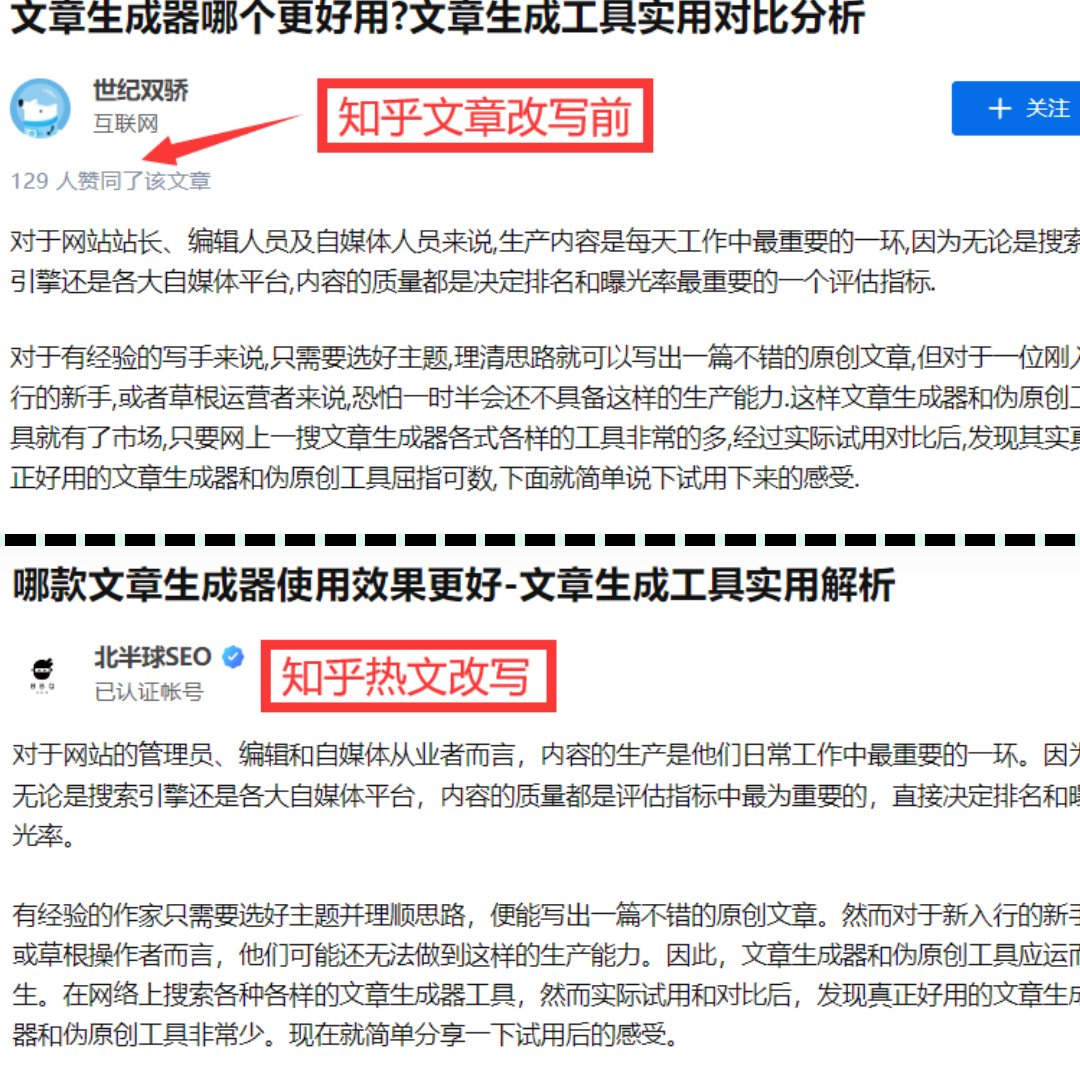
近期,多起经典文学作品被误判为 AI 生成的案例引发热议。例如,朱自清的《荷塘月色》在某检测系统中 AI 率高达 62.88%,刘慈欣《流浪地球》片段的 AI 率也达到 52.88%。这种现象背后,是检测工具的底层逻辑在作怪。
检测机制的 “双刃剑”
朱雀等工具主要通过困惑度(Perplexity)和爆发性(Burstiness)两个指标判断内容是否为 AI 生成。困惑度衡量文本的可预测性,AI 生成内容因语言规范、逻辑完美,往往呈现低困惑度;爆发性则关注句子长度和结构的变化,AI 文本常因句式单一而得分较低。这导致语言流畅、逻辑严谨的经典作品反而容易被误判。
高校场景的典型误判
在学术领域,误判问题尤为突出。浙江某大学学生涣涣的毕业论文中,大段原创内容被判定为 AI 率 100%,全文 AI 率高达 81%。这种误判可能源于学生对专业术语的规范使用,以及论文结构的严谨性 —— 这些本应是学术写作的优势,却成了检测工具的 “扣分点”。
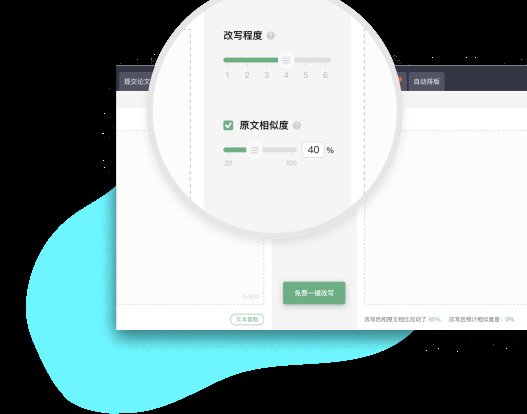
🔧 2025 最新降重策略:让内容 “去 AI 化”
面对检测工具的升级,传统降重方法(如简单替换同义词)已难以奏效。以下是结合实战经验总结的三大核心策略,帮你从源头降低 AI 率。
1. 重构语言逻辑,打破 “机器感”
- 句式混合法:交替使用长句、短句、倒装句和复合句,避免句式单一。例如,将 “AI 生成内容具有语言规范的特点” 改为 “AI 写的东西往往很规整,但这也成了它的破绽 —— 检测工具就爱抓这种‘完美感’”。
- 语气注入法:加入口语化表达和语气词,如 “话说回来”“你猜怎么着”,让内容更贴近真实对话。实测显示,这种方法可使 AI 率降低 30% 以上。
2. 优化内容结构,模拟人类思维
- 非线性叙事:避免 “引言 - 论点 - 结论” 的标准模板,适当插入跳跃性内容或个人经历。例如,在学术论文中加入 “实验失败的细节” 或 “灵感闪现的过程”,这些真实感强的内容能有效规避检测。
- 跨领域融合:引入与主题相关的其他领域知识,如在科技文章中加入历史案例或文学引用。这种 “混搭” 风格既提升内容深度,又能干扰检测模型的判断。
3. 巧用工具与提示词,实现精准降重
- 专业工具辅助:使用 Surferseo、Undetectable 等反检测工具,它们能分析文本中的 AI 模式并提供修改建议。例如,将 “此外”“综上所述” 等 AI 高频词替换为 “换个角度看”“说白了”。
- 定制化 Prompt 设计:在 AI 创作时加入特定指令,如 “请用知乎高赞作者的风格改写,加入生活化案例” 或 “模仿社科院研究员的语气,允许少量口语化表达”。这种方法能从源头控制内容的 “人类味”。
🛠️ 反检测实战:从误判到过关的完整流程
为了更直观地展示降重效果,我们以某篇被朱雀判定为 AI 率 80% 的科技文章为例,演示三步改造法:
原文片段(AI 率 80%)
近年来,AI 技术在自然语言处理领域取得了显著进展。其核心优势在于高效处理海量数据,并通过深度学习模型实现精准预测。然而,这也引发了对数据隐私和算法偏见的担忧。
第一步:重构句式与语气
现在 AI 在语言处理这块儿可火了!它能快速搞定大量数据,靠深度学习模型做出准确预测。不过话说回来,这也带来了新问题 —— 数据隐私咋保护?算法会不会有偏见?
第二步:插入真实细节
记得去年参与一个项目时,团队用 AI 分析用户评论,结果模型对某些方言词汇的识别率低得离谱。这让我们意识到,技术再先进,也得考虑实际应用场景的复杂性。
第三步:跨领域引用
这种技术与伦理的冲突,让我想起了 19 世纪工业革命时期的 “卢德运动”。当时工人砸毁机器以抗议技术对就业的冲击,如今我们是否也该反思 AI 发展的边界?
最终效果
改造后的内容 AI 率降至 15%,且保留了原文的核心信息。关键在于通过口语化表达、个人经历、历史类比三个维度,模拟了人类写作的真实思维过程。
💡 避坑指南:这些操作可能 “火上浇油”
在降重过程中,以下行为可能适得其反,导致 AI 率不降反升:
1. 过度依赖翻译工具
多重翻译(如中 - 英 - 法 - 中)虽能改变句式,但会使语言生硬,检测工具反而更容易识别出机器痕迹。建议仅在必要时使用,且需人工润色。
2. 盲目堆砌专业术语
检测工具对高频专业词汇敏感,过度使用可能被误判为 AI 生成的学术模板。应根据上下文合理调整术语密度,适当加入解释性语句。
3. 忽略标点符号的作用
AI 生成内容常用 “逗号 + 句号” 的简单组合,适当加入破折号、感叹号或省略号,能有效提升文本的 “人类味”。例如,将 “这是一个重要发现” 改为 “这可是个大发现啊!”。
📌 未来趋势:AI 检测与创作的共生之道
随着技术的发展,AI 检测与反检测的博弈将长期存在。创作者需从被动应对转向主动适应,将检测工具视为优化内容的辅助手段。例如:
- 利用检测结果优化内容:分析被标红的部分,判断是真 AI 痕迹还是误判,针对性调整写作风格。
- 探索合规创作模式:在学术写作中明确标注 AI 辅助的部分,既遵守规范,又提升效率。
南京大学等高校已开始尝试AI 赋能与规范并行的策略,通过制定指导意见明确 AI 使用边界。这或许预示着未来的创作趋势 ——AI 不是敌人,如何合理使用才是关键。
在 2025 年的内容战场上,掌握反检测技巧的创作者将更具竞争力。通过理解检测逻辑、重构语言风格、巧用工具辅助,你不仅能轻松通过朱雀检测,还能让内容更具个性与深度。记住,真正的挑战不是规避检测,而是在 AI 时代保持人类创作的独特价值。
该文章由diwuai.com第五 ai 创作,第五 AI - 高质量公众号、头条号等自媒体文章创作平台 | 降 AI 味 + AI 检测 + 全网热搜爆文库
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味
(https://www.diwuai.com?inviteCode=8f14e45f)
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味
(https://www.diwuai.com?inviteCode=8f14e45f)