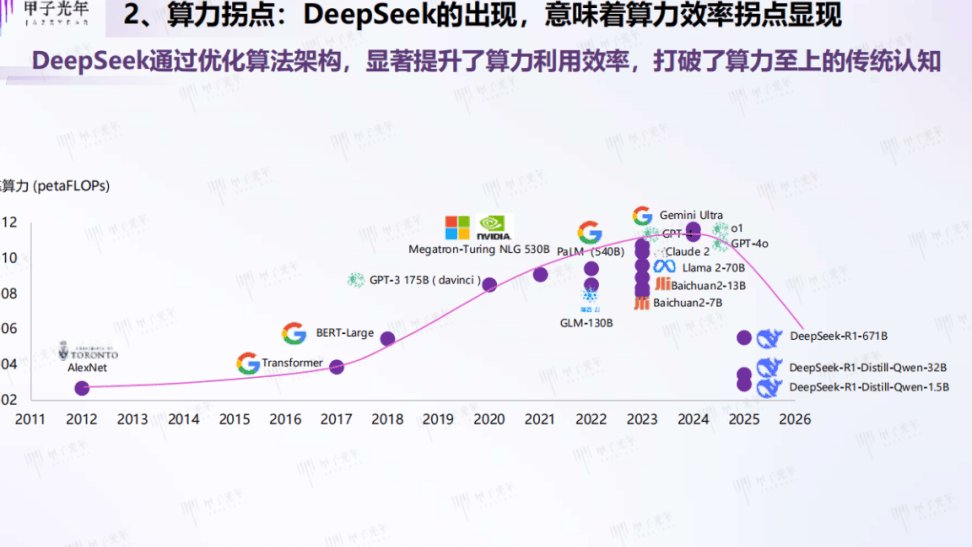
算法改进对 AI 率的影响:2025 年最新研究成果
800 阅读
98 评论
🔍 算法改进对 AI 率的影响:2025 年最新研究成果
2025 年,人工智能领域的算法改进呈现出爆发式增长,从底层架构创新到行业应用落地,每一次技术突破都在重新定义 AI 效率的边界。这一年,研究人员不再局限于参数规模的竞赛,而是通过架构杂交化、训练集约化和场景深挖化三大方向,推动 AI 从 “通用能力” 向 “垂直效能” 跃迁。
🚀 核心技术突破:架构创新重塑效率边界
2025 年的算法改进以混合架构为核心,Transformer、Mamba、MoE 等组件的灵活搭配成为主流。腾讯混元 T1 正式版采用的 Hybrid-Mamba-Transformer 架构,通过三大创新打破了 “提升性能必增成本” 的困境:
- Mamba 组件专攻长序列,以普通 Transformer 1/5 的计算量维持信息连贯性,解决了数学证明、代码分析中的 “上下文丢失” 问题。
- 动态路由的 MoE 系统自动激活特定任务专家模块,在保持 32k 上下文窗口的同时,将解码速度提升 2 倍。
- 内存优化设计使单次训练成本下降 40%,推理能耗仅为同类模型的 60%。
这种架构创新直接体现在性能指标上:混元 T1 在 MATH-500 评测中取得 96.2 分,可解包含 10 步以上推导的奥数难题;在 LiveCodeBench 评测中,其代码生成质量超越 O1,尤其在动态调试建议方面展现独特优势。更值得关注的是,其 API 价格体系较前代下降 50%,中小企业可凭千元预算启动专业级 AI 应用开发,真正实现了技术普惠。
🔬 效率提升机制:从理论到实践的量化突破
算法改进对 AI 效率的提升可分为集约边际与广延边际两大维度:
- 集约边际通过降低输入需求(如训练数据量、算力消耗)或在同等资源下提升性能实现效率提高。例如,PyTorch 团队重写的 SAM 模型,通过 GPU 量化、标度点积注意力(SDPA)等技术,将推理速度提升 8 倍,且准确率无损失。
- 广延边际则赋予模型新能力,如解决此前无法处理的问题类型。谷歌 DeepMind 为几何证明生成合成数据,微调后的模型在国际数学竞赛中达到银牌水平,表明合成数据可用于扩展模型能力边界。
具体到技术实现,以下方向成为效率提升的关键路径:
- 稀疏性利用:混合专家(MoE)模型通过动态计算图,在固定计算成本下比同等规模的非 MoE 模型获得更高准确率。塔尔・施尼策尔等人的研究显示,从专家池中识别 “最佳模型” 可显著提升性能。
- 目标函数创新:隐式奖励建模的大语言模型引入多维度标注数据的顺序对齐,使模型处理多目标任务更灵活高效,尤其在医疗康复和认知障碍治疗中表现突出。
- 低精度计算:torchao 库支持 float8、int4 等低精度数据类型,在 LLaMA 3 70B 模型的预训练中,将计算速度提升 1.5 倍,同时显存占用大幅降低。
🌐 行业应用:从实验室到商业场景的价值转化
算法改进的价值正在各行业加速落地,以下案例展现了技术与场景的深度融合:
- 医疗领域:唯迈医疗的 We Navigation 介入手术自动导航技术,通过 AI 自动分割与分析,将血管轮廓识别精度提升至 0.1 毫米级,手术配准时间从人工操作的数十分钟缩短至 3 秒。该技术无需改造现有 DSA 设备,已在多家三甲医院实现临床应用。
- 制造业:雅迪 “云销通” APP 接入 PolarDB for AI 后,通过向量检索与大语言模型推理,实现 10 万多名销售人员的实时数据分析,数据查询准确率超 90%,运维成本降低 45%。
- 广告领域:某 DSP 广告厂商利用 PolarDB for AI 的实时推理能力,将广告点击率预测响应时间压缩至毫秒级,广告转化率提升 27%,系统稳定性在高流量时段提升 40%。
⚠️ 挑战与未来:技术红利背后的隐忧与机遇
尽管算法改进带来了显著的效率提升,但行业仍面临多重挑战:
- 数据硬约束:兰德公司报告指出,数据修剪技术虽可将训练成本降至现有水平的 1%,但需覆盖多领域知识,核心挑战在于优化数据选择以最大化信息增益。
- 商业可行性:算法扩展失败可能引发成本失控,例如某自动驾驶公司因训练数据偏差导致模型泛化能力不足,最终研发成本超支 300%。
- 伦理与安全:深度伪造检测、算法偏见等问题日益凸显。信通院发布的自动驾驶 AI 安全评估白皮书明确要求,L4 级以上系统需通过多模态检测框架,确保生理信号、图像伪影等多维度的安全合规。
展望未来,2025 年的算法改进呈现三大趋势:
- 架构杂交化:73% 的新发布模型采用混合架构,Transformer、Mamba 等组件的协同将成为常态。
- 训练集约化:96.7% 的算力投入强化学习阶段,形成 “预训练打基础 - RL 精调出性能” 的新范式。
- 场景深挖化:专业推理模型市场规模预计 2026 年突破千亿元,数学、代码、科学等 “高壁垒、高价值” 领域成为竞争焦点。
📊 总结:效率革命的终极目标
算法改进对 AI 率的影响,本质上是人类对计算效率的极致追求。从兰德公司的理论框架到腾讯混元 T1 的商业落地,从 PyTorch 的底层优化到唯迈医疗的临床突破,每一次技术进步都在重新定义 AI 的可能性。正如 MIT 团队开发的 SketchAgent 系统,通过模拟人类素描的逐笔迭代过程,AI 正从工具进化为协作伙伴。
在这场静默的革命中,“单位算力效能” 与 “垂直场景穿透力” 已成为新的竞争焦点。对于企业而言,拥抱算法改进不仅是技术升级,更是战略选择 —— 唯有将算法创新与场景需求深度绑定,才能在 AI 驱动的产业变革中占据先机。
该文章由diwuai.com第五 ai 创作,第五 AI - 高质量公众号、头条号等自媒体文章创作平台 | 降 AI 味 + AI 检测 + 全网热搜爆文库
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味